Publié le 30 avril 2025 à 12:04
Ahmed-Amine HOMMAN, Research Project Manager
En quelques années, l'IA générative est passée d'un sujet de laboratoire à une technologie omniprésente dans notre quotidien. Créer un texte en quelques secondes, générer une image à partir d'une simple description, produire une musique inédite : ces prouesses, jadis dignes de la science-fiction, sont aujourd'hui accessibles à tous. Mais que se cache-t-il réellement sous le capot de ces modèles capables d'inventer, d'adapter et de mimer la créativité humaine ?
L'intelligence artificielle a longtemps été perçue comme un outil d'analyse, d'optimisation et de classification. Mais depuis quelques années, une révolution silencieuse s'est amorcée : l'émergence de l'IA générative. Contrairement aux modèles traditionnels, qui se limitent à reconnaître et organiser l'information, ces nouveaux systèmes sont capables de créer de toutes pièces du texte, des images, du son ou encore du code.
Ce bond technologique a été rendu possible par des avancées dans l'apprentissage automatique et la disponibilité de gigantesques volumes de données. L’essor des modèles comme GPT pour le texte, Stable Diffusion pour l'image ou encore les encodeurs sémantiques comme CLIP marque une nouvelle ère : celle d'une intelligence artificielle qui ne se contente plus d'exploiter l'existant, mais qui peut produire du contenu original, parfois surprenant.
Dans cet article, nous allons explorer les fondements de cette technologie en distinguant trois grandes catégories de modèles : les LLMs (Large Language Models), qui manipulent le texte et sont capables de raisonnement (tels les modèles derrière les agents conversationnels comme ChatGPT par exemple) ; les Diffuseurs, qui génèrent des images et des vidéos ; et les Encodeurs, qui transforment des données non structurées telles que du texte ou des images en représentations vectorielles mathématiques permettant d’en extraire plus facilement le sens. Avant de plonger dans ces différentes familles, prenons un moment pour comprendre ce qui distingue l'IA générative des approches plus classiques.
L'intelligence artificielle, vaste domaine d'étude, peut être appréhendée à travers le prisme de deux grandes catégories : l'IA discriminative et l'IA générative. Cette distinction, fondamentale, réside dans leur finalité et leur approche du traitement des données.
L'IA discriminative se concentre sur la classification et l'étiquetage de données existantes. Son rôle consiste à identifier des motifs, des structures, et à attribuer des catégories ou des probabilités à ces données. Par exemple, face à une image, elle déterminera s'il s'agit d'un chat, d'un chien, ou d'un autre objet. Son champ d'application s'étend à la reconnaissance d'objets, la détection de spam, ou encore l'analyse de sentiments.
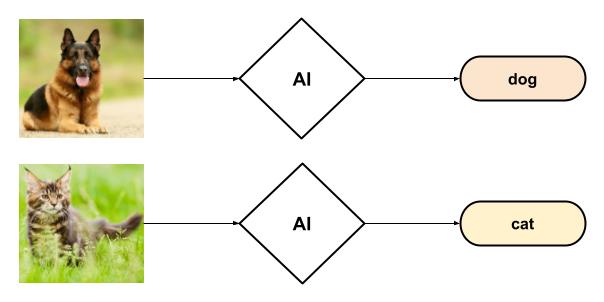
L'IA générative, à l'inverse, a pour vocation la création de nouvelles données. Elle s'appuie sur les schémas et les structures appris pour synthétiser des informations originales, qu'il s'agisse de texte, d'images, de musique ou d'autres formes de contenu. Ainsi, plutôt que de simplement identifier un chat sur une image, elle sera capable de générer une image d'un chat, avec une apparence inédite.
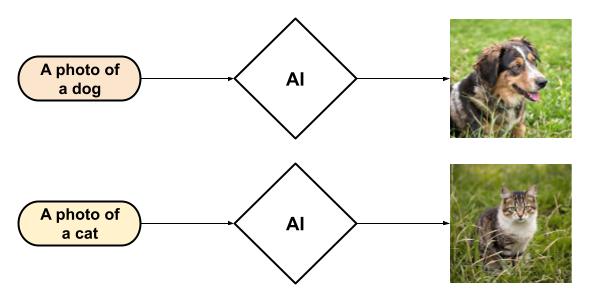
Il est important de souligner que la distinction entre IA générative et discriminative ne tient pas tant aux modèles, algorithmes ou architectures employés, mais plutôt à leur utilisation et à l'objectif poursuivi. Un même modèle peut être exploité de manière discriminative ou générative, selon la tâche à laquelle il est assigné.
Prenons l'exemple de l'analyse de séries temporelles. Un modèle prédictif peut être utilisé de manière discriminative pour prédire la valeur suivante d'une série. Cependant, en intégrant cette prédiction à la série et en réitérant le processus, le modèle devient capable de générer une séquence de données, se rapprochant ainsi d'une approche générative.
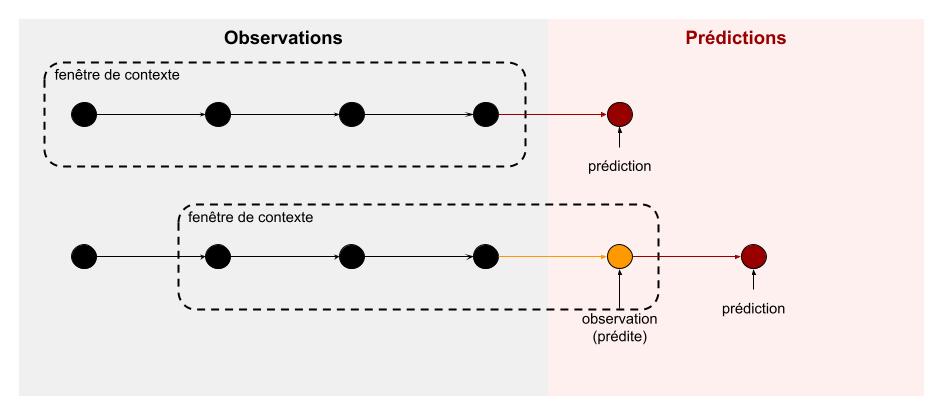
En bref, l'IA discriminative excelle dans la reconnaissance et la classification, tandis que l'IA générative se distingue par sa capacité à créer. Les deux approches sont essentielles, mais leurs applications et leurs implications diffèrent considérablement.
L’IA Générative, comme toute avancée technologique et scientifique, n’est pas sortie de nulle part, et s’inscrit dans une longue lignée d’avancées et de découvertes qui ont pavé le chemin pour arriver aux modèles “précurseurs”, qui peuvent être considérés comme les premiers modèles d’IA Générative dans le sens où on l’entend aujourd’hui.
Contrairement à une idée reçue, l'IA générative n'a pas éclos en 2022 avec l'arrivée de ChatGPT ou la publication de Stable Diffusion. De nombreux modèles génératifs existaient déjà bien avant, capables de créer divers types de données.
Dans le domaine du traitement du langage naturel, la Latent Dirichlet Allocation (LDA), par exemple, présentée en 2001 à la conférence NeurIPS puis en 2003 dans le Journal of Machine Learning Research (avec, parmi ses auteurs, un certain Andrew Ng, dont vous avez peut-être déjà entendu parler 😉), parvenait à générer du texte similaire au corpus d'entraînement grâce à des méthodes probabilistes. Bien que le texte généré ne fût pas toujours intelligible stricto sensu, les mots produits respectaient une distribution de probabilité d'occurrence proche du corpus d'entraînement, permettant ainsi de deviner le thème abordé.
Du côté de la génération d'images, les Generative Adversarial Networks (GAN), introduits en 2014 par Ian Goodfellow et ses collaborateurs (parmi lesquels figure Joshua Bengio, figure éminente du domaine), réussissaient à reproduire de manière convaincante des images similaires à celles observées durant leur entraînement. En particulier, entraînés sur des photographies de portraits, ces modèles parvenaient à générer des visages synthétiques saisissants de réalisme.
Dans le domaine de l'encodage du langage, les premières approches représentaient les textes en comptant l’occurrence des mots dans le corpus, comme avec TF-IDF, proposé en 1988. L’émergence de l’apprentissage profond permit ensuite de produire des vecteurs denses et plus riches, à l’image de Word2Vec (2013), qui capturait le sens des mots via un réseau de neurones peu profond. Cette approche fut étendue aux phrases et documents avec Doc2Vec, proposé en 2014. Si ces modèles rendaient enfin le langage manipulable numériquement, ils restaient limités : incapables de traiter efficacement les dépendances à longue distance et de saisir la polysémie du langage, où un même mot change de sens selon le contexte.
L'année 2017 marque un tournant décisif avec la publication de Attention is All You Need, introduisant l'architecture des Transformers. Son innovation clé, le mécanisme d’attention, permet aux modèles de repérer les relations entre des éléments distants au sein d’une séquence. Appliqué au langage naturel, ce mécanisme facilite la compréhension des liens entre des mots éloignés dans une phrase. Par exemple, dans "Paul est parti en voyage, il reviendra demain", l’attention permet d’associer "il" à "Paul", une tâche où les modèles précédents échouaient souvent. Cette avancée a ouvert la voie aux premiers modèles d’IA capables d’analyser le langage avec une précision inédite, amorçant la révolution des intelligences artificielles génératives.
Dans le domaine du langage naturel, le modèle "précurseur" fut le Generative Pretrained Transformer (GPT, cela vous rappelle quelque chose ?), ou "GPT 1", publié en 2018 par des chercheurs d'OpenAI (dont Ilya Sutskever, qui a récemment fait parler de lui pour sa tentative ratée d’expulsion de Sam Altman du comité directeur d’OpenAI 😅). Ce modèle, premier grand nom de la catégorie désormais connue sous le nom de Large Language Models, était capable de générer du texte intelligible et grammaticalement correct. Il pouvait compléter un texte fourni en entrée ou, plus impressionnant encore, générer du texte de toutes pièces. Ses itérations successives, GPT-2 et GPT-3, ont permis d'aboutir à GPT-3.5, qui alimentait la première version de ChatGPT.
Dans le domaine de la génération d'images, le modèle précurseur fut Stable Diffusion, introduit en 2022 par un groupe de chercheurs qui ont ensuite fondé l'entreprise Stability AI, un acteur majeur du secteur. Ce modèle permettait de générer, à partir d'une description textuelle, une image en la "reconstruisant" à partir d'une image entièrement bruitée (c'est-à-dire ne contenant aucune information).
Enfin, dans le domaine de la représentation vectorielle (encodeurs), le premier modèle précurseur fut BERT (Bidirectional Encoder Representations from Transformers), introduit en 2018 par des chercheurs de Google. Ce modèle a révolutionné l’analyse du langage naturel en permettant de représenter avec précision le sens d’un texte sous forme de vecteurs dans un espace dit latent. Concrètement, BERT transforme les mots et phrases en représentations numériques qui capturent leurs significations et relations contextuelles, facilitant ainsi leur traitement par des algorithmes. Son introduction a ouvert la voie à une multitude de modèles capables d’encoder non seulement du texte, mais aussi d’autres types de contenu comme la musique, les images et les vidéos, rendant ces données exploitables par d’autres modèles prédictifs avec une finesse inédite.
Ces modèles précurseurs ont ensuite été améliorés par itérations successives, intégrant de nombreuses optimisations, issues du même domaine ou d'autres types de modèles, pour aboutir aux IA d'aujourd'hui, qui sont nettement plus performantes que leurs prédécesseurs, atteignant des performances aux benchmarks principaux de la communauté bien supérieures pour une fraction du coût en ressource.
Dans tous les domaines que nous avons abordés, une augmentation spectaculaire des performances a été observée au fil des itérations successives de chaque modèle. En effet, les publications se sont succédé à un rythme effréné, chacune présentant un nouveau modèle. Ces modèles ont soit dépassé de manière significative les meilleurs modèles précédents en termes de scores sur les principaux benchmarks de la communauté, soit réduit considérablement les coûts nécessaires pour atteindre des performances équivalentes, soit carrément les deux à la fois !
Dans le domaine des LLM, en deux ans seulement, les meilleurs modèles ont atteint des sommets d'intelligence sur les benchmarks « classiques » (MMLU pour la compréhension multilingue, HellaSwag testant le raisonnement, MATH pour les questions mathématiques, etc..). De nouveaux benchmarks, présentant des problèmes à résoudre encore plus complexes, de niveau doctoral, ont même dû être conçus pour les départager (un bel exemple est le benchmark Humanity Last Exam, composé de questions ardues sur un vaste panel de sujets). Parallèlement, les prix proposés par les principales API offrant les services de ces modèles ont chuté de plusieurs ordres de grandeur.
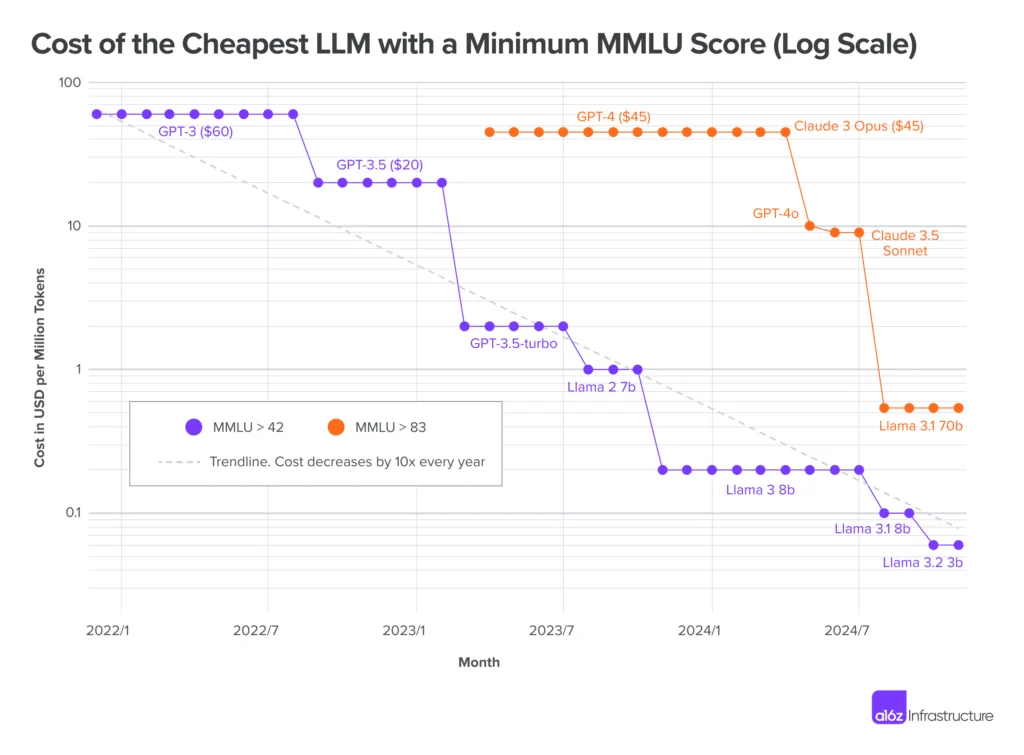
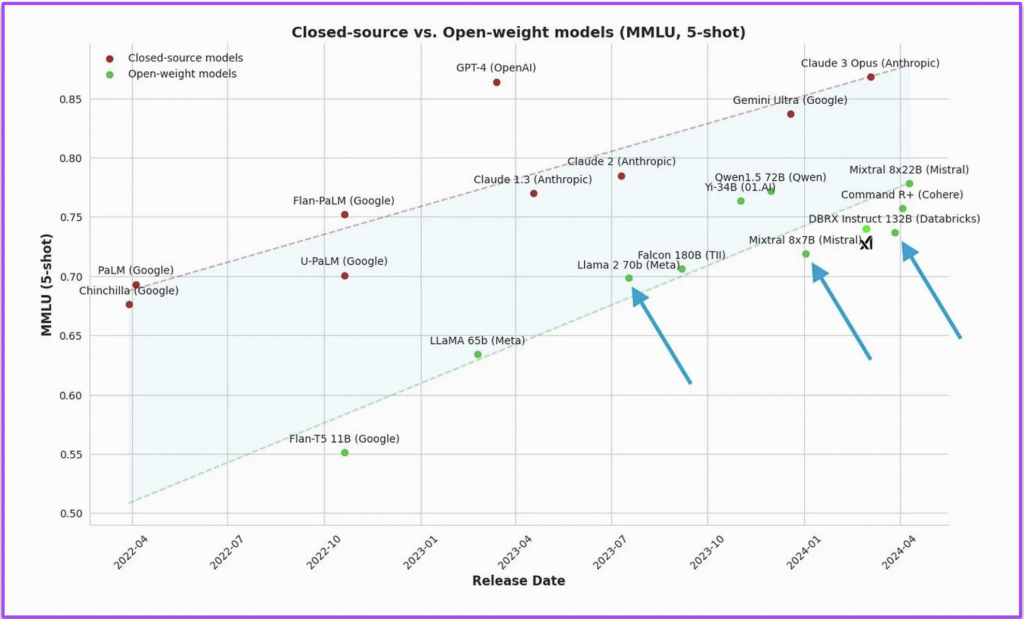
Les deux graphiques ci-dessus sont emblématiques : du côté gauche, on voit que le coût par token (unité de mesure de coût dans le domaine des LLMs) a score MMLU égal a été divisé par 100 alors que du côté droit, on observe une augmentation linéaire des scores MMLUs des meilleurs modèles.
Dans le domaine des Diffuseurs, les performances ont également explosé, et les modèles sont désormais capables de générer des images d'une qualité époustouflante et de comprendre des prompts très complexes. Cependant, contrairement aux LLM, les coûts n'ont pas diminué dans les mêmes proportions, à niveau de performance constant, et les modèles sont devenus beaucoup plus volumineux.
En témoignent toutes les images ci-dessous, qui ont été générées à partir de la même description :
A brave musketeer cat walking in the streets of a fantasy version of renaissance paris by night



Les images ci-dessus illustrent l'évolution frappante des capacités des Diffuseurs : chaque image a été générée par l'une des versions de Stable Diffusion, de la plus ancienne, à gauche, à la plus récente, à droite. Nous remarquons le gain de qualité, d'esthétique et de précision impressionnant entre chaque version, plus particulièrement pour le passage à la version 3 (image de droite) qui est impressionnante de réalisme.
Les modèles utilisés pour générer les images ci-dessus sont des versions successives du modèle précurseur Stable Diffusion disponibles sur la plate-forme Replicate. Le modèle ayant généré l'image de droite est une version améliorée et optimisée du modèle originelle Stable Diffusion se trouvant sur cette page. Le modèle correspondant à la seconde image (au centre) est Stable Diffusion XL, disponible sur cette page. Enfin le troisième modèle, le plus récent, correspond à Stable Diffusion 3.5 - large, la meilleure variante de la troisième mouture de Stable Diffusion.
Enfin, les Encodeurs n'ont pas été en reste, et ont vu leurs performances décoller et leurs coûts plonger, tout comme les LLM. L'exemple le plus frappant est la publication de ModernBERT. Ce modèle reprend exactement l'architecture du modèle précurseur BERT, mais incorpore toutes les optimisations développées depuis sa présentation. Résultat : une augmentation significative de tous les scores (jusqu'à 50 % de plus pour certaines métriques) avec une efficacité et un coût en ressources de calcul grandement diminué.
Nous avons vu que la situation actuelle résulte d’un long parcours ayant mené au développement de modèles extrêmement puissants et intelligents, capables de générer du contenu pertinent, informatif, esthétique et bien plus. La question que l’on peut se poser désormais est la suivante : Et maintenant ? 🤔
En effet, avoir des modèles qui comprennent ce que l’on dit et répondent, c’est bien. Avoir des modèles qui génèrent de belles images, c’est top. Disposer de modèles représentant correctement le sens des textes et des images dans des vecteurs… pourquoi pas. Mais comment peut-on mettre tout cela en musique ? À quoi tout cela peut-il servir ?
Pour répondre à cette question, prenons un exemple que tout le monde connaît : ChatGPT. Comment cette application utilise-t-elle toutes les avancées technologiques dont nous avons parlé pour fournir son service, si apprécié des internautes ? C’est ce que nous allons voir.
Nous précisons que nous ne travaillons pas en collaboration avec OpenAI et n'avons pas eu accès au code source de l'application ChatGPT. Ce qui va suivre repose donc sur des suppositions éclairées, fondées sur notre connaissance du domaine et de ses usages. Nous décrirons le fonctionnement "générique" d'une application de ce type, sans prétendre dévoiler toutes les optimisations ou subtilités spécifiques à ChatGPT, que nous n'avons ni la prétention de connaître, ni, peut-être, de comprendre.
Tout d’abord, ChatGPT n’est pas une IA en soi. Contrairement à ce que beaucoup pensent, ainsi qu’à l’usage courant du terme, ChatGPT est une application (web, Android, iOS). Comme toute application, elle est codée dans un langage standard avec des instructions déterministes et, à proprement parler, ne génère aucun contenu par elle-même. Sa particularité réside dans le fait qu’elle repose sur des modèles d’IA générative pour fonctionner. Ce ne sont donc pas les lignes de code de l’application qui produisent les réponses, mais une API – en l’occurrence celle d’OpenAI – qui expose ces modèles et leur permet d’être sollicités à la demande. En d’autres termes, ChatGPT est un wrapper (enveloppe logicielle) permettant d’interagir avec ces modèles.
Une API (Interface de Programmation Applicative) est un outil qui permet à deux logiciels de communiquer entre eux. Plutôt que d’intégrer directement un système complexe dans une application, une API offre un moyen d’y accéder à distance, en envoyant des requêtes et en recevant des réponses. Une analogie courante est celle d’un restaurant : l’API joue le rôle du serveur, qui prend votre commande, la transmet à la cuisine et vous rapporte le plat une fois préparé. De la même manière, une API permet à un logiciel d’accéder à un service externe sans en connaître tous les détails internes, simplifiant ainsi son développement et son intégration.
Mais comment procède-t-elle alors ? Et bien elle combine les capacités de tous les types de modèles (LLM, Diffuseur, Encodeur) que nous avons vu précédemment pour fournir son service. Détaillons son fonctionnement en fonction des différents types d’usages auxquels elle répond.
L’utilisation standard correspond à une conversation avec l’IA, soit un échange de textes. Dans ce cas, lorsque ChatGPT reçoit votre message, elle va l'envoyer au LLM hébergé par l’API OpenAI (probablement GPT-4o-mini si vous êtes sur la version gratuite, GPT-4o si vous êtes sur la version payante) qui va y répondre (nous verrons dans un article ultérieur les détail de cette opération). ChatGPT va alors récupérer la réponse et l’afficher sur votre écran.
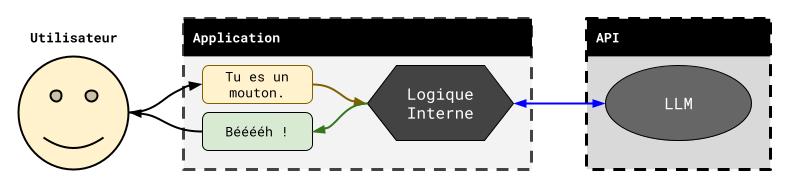
Le schéma ci-dessus illustre ce fonctionnement : l’application reçoit votre requête (flèche marron), l’envoie au LLM (flèche bleue) puis vous renvoie la réponse de ce dernier (flèche verte).
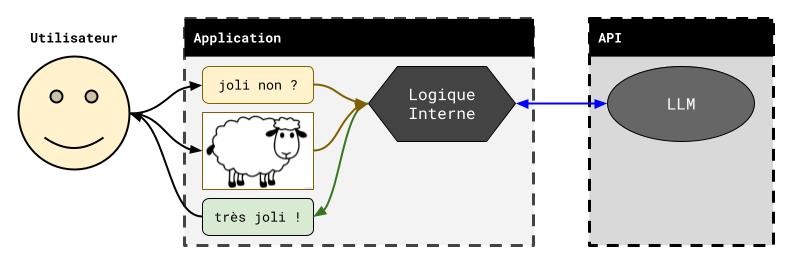
ChatGPT vous permet aussi de fournir des images dans vos conversations. En effet, les modèles GPT-4o sont multimodaux et peuvent “comprendre” des images. Dans ce cas, le principe est similaire à celui du cas standard, et l’image que fournissez est transmise avec votre requête textuelle au LLM (cf. le schéma ci-dessous).
ChatGPT propose aussi des services de création d’image : vous pouvez lui demander de générer l’image de votre choix, et, au bout d’un moment, vous allez recevoir une image correspondant (peu ou prou) à ce que vous avez décrit. Dans ce cas, le processus suivi, un peu différent, est détaillé ci-dessous en conjonction au schéma qui suit :
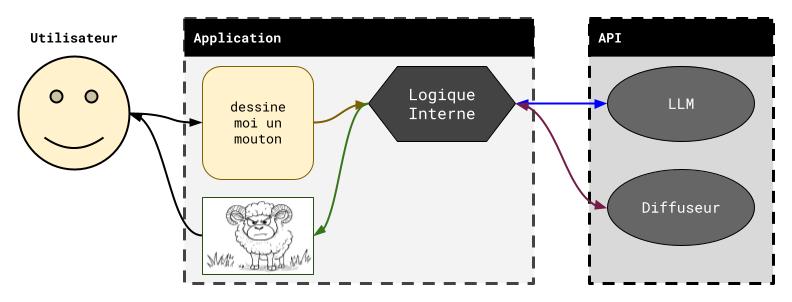
Depuis peu, OpenAI a fait évoluer son service de génération d’images. La fonctionnalité, autrefois motorisée par DALL-E 3, repose désormais sur une déclinaison de GPT-4o spécialisée dans la création d’images. Ce nouveau modèle améliore nettement la qualité des résultats et pourrait introduire quelques différences dans le processus interne. Toutefois, le principe général présenté ici reste pleinement valable.
Enfin, ChatGPT vous permet aussi de fournir des documents que l’IA pourra consulter pour mieux vous répondre. Ce cas-là nécessite de faire appel à un Encodeur, qui va représenter le document fourni via un ensemble de vecteurs latents associés à chacune de ses parties. L’application pourra alors utiliser ces vecteurs pour déterminer les parties pertinentes du document à fournir au LLM pour sa réponse.
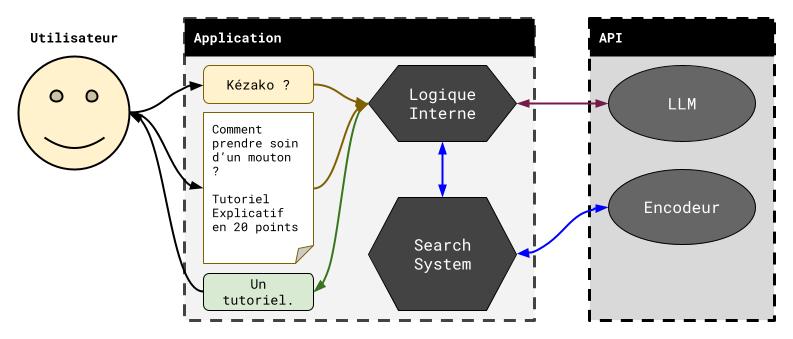
Le schéma ci-dessus illustre ce procédé : l’application va faire appel à un outil de recherche (flèche bleue) qui va s’occuper de récupérer le contenu du document et de l’encoder, grâce à l’Encodeur de l’API. Ce moteur de recherche va ensuite pouvoir fournir le contenu pertinent du document à chacune de vos requêtes, que l’application pourra joindre à cette dernière et envoyer au LLM (flèche violette), qui aura donc l’information nécessaire pour vous répondre.
Le processus est similaire lorsque vous demandez à ChatGPT d’appuyer ses réponses via une recherche internet : au lieu de rechercher au sein des documents que vous avez fourni, le moteur de recherche va effectuer une recherche internet et ajouter le contenu pertinent par rapport à votre requête à ce qu’il envoie au LLM.
Bien entendu, ce que nous avons décrit ici pour ChatGPT s’applique aussi à tout agent conversationnel fournissant plusieurs types de services d’IA Générative. Le Chat par exemple, développé par l’entreprise (française) Mistral AI, adopte un fonctionnement similaire, en utilisant ses propre modèles : Mistral-Large ou Mistral-Small comme LLM, Mistral-Embed comme Encodeur et les modèles FLUX comme Diffuseurs (via un partenariat avec Black Forest Lab, les propriétaires de ces derniers).
Nous avons effectué ensemble un petit panorama de ce que sont les IA Génératives. Nous avons défini les trois grands modèles que nous allons considérer dans cette série, à savoir les LLMs (produisant du texte), les Diffuseurs (produisant des Images) et les Encodeurs (produisant des représentations vectorielles). D’autres types de modèles, produisant d’autres types de contenu (vidéos, modèles 3D, sons, séries temporelles, etc…) existent et représentent de nombreux cas d’usages intéressants, mais nous allons les laisser de côté pour le moment.
Nous avons ensuite effectué un historique décrivant les différents jalons scientifiques et technologiques qui ont permis l’avènement des IAs Génératives, et nous avons vu que cet avènement correspond à un long processus itératif plutôt qu’une découverte spontanée. Nous avons ensuite discuté de l’essor des performances des modèles de référence, et notamment de la façon dont les capacités de ces derniers ont décollé en quelques années, combinée à une véritable chute des prix et des coûts d’utilisation.
Enfin, nous avons fourni un exemple concret en détaillant le fonctionnement de l’application ChatGPT, désormais connue de tous. Nous avons expliqué comment cette application, qui n’est pas un modèle d’IA en soi, utilise les capacités de tous ces différents modèles (LLM, Diffuseur, Encodeur) pour fournir son service si apprécié.
Cet article est un article introductif dans le cadre d’une série de publications autour de l’IA Générative. Nous allons nous intéresser plus en détail aux fonctionnements de tous ces modèles dans des publications ultérieures, et fournir quelques cas d’applications et d’usages concrets. Ainsi, restez à l’écoute, car ce n’est que le commencement !
{kind=link}