Étude : Automatisation de l’analyse de KPIs, un essai avec Chat GPT d’Open AI.
Par Ahmed-Amine Homman, Research Project Manager chez ClaraVista
Titulaire d'un doctorat en Mathématiques Appliquées obtenue à l'Ecole des Ponts ParisTexh (Université Paris-Est) et ancien élève de l'Ecole Normale Supérieure de Lyon, Ahmed-Amine coordonne l'effort de R&D de l'entreprise depuis 4 ans. Dans le cadre de ses missions, il a été amené récemment à investiguer les capacités des grands modèles de langages tels que chatGPT, Bard ou LLama afin d'étudier leurs éventuelles applications dans le domaine du retail et du marketing. Il partage avec vous quelques-unes de ses trouvailles dans cet article.
Introduction
Le 30 novembre 2022, OpenAI a dévoilé
chatGPT, sa nouvelle application basée sur GPT-3.5, un agent conversationnel surpuissant capable de fournir des réponses précises et détaillées à toutes sortes de demandes, disponible à l'époque uniquement sur le web. Quatre mois plus tard, OpenAI a lancé
GPT-4, une version encore plus puissante, compétente et érudite de son agent conversationnel.
Depuis lors, une véritable course à l'intelligence artificielle générative s'est enclenchée, avec les géants du secteur tels qu'Amazon, Google, Microsoft, Meta, et d'autres, qui ont lancé leurs propres concurrents à chatGPT (comme
Bard chez Google), des outils révolutionnaires basés sur les modèles GPT d'OpenAI (comme
Copilot pour Microsoft et
GitHub Copilot pour GitHub), ou même des modèles concurrents (comme Llama et
LLama-2 chez Meta), ainsi que des produits basés sur ces modèles concurrents (comme
CodeWhisperer pour l'assistance à la programmation chez Amazon).
De plus, des acteurs moins connus du domaine ont pu profiter de cette soudaine popularité en proposant leurs propres modèles concurrents à ceux de OpenAI et parfois des applications alternatives à chatGPT. Parmi ces nouveaux produits, citons
Claude, développé par Anthropic, une entreprise dans laquelle Amazon a récemment
investi massivement, qui représente une alternative sérieuse à chatGPT.
Cohere, quant à elle, propose des modèles génératifs de langage puissants via
une API concurrente à celle d'OpenAI. De nombreux modèles open-source rivalisent également en termes de performances, tels que
les modèles Falcon du
Technology Innovation Institute, ou plus récemment
les modèles Mistral de l'entreprise française Mistral AI, qui a récemment
levé des fonds en juin 2023 et dévoile déjà des modèles très performants.
Dans cet environnement en constante évolution, le secteur du conseil n'est pas resté inactif. Les grands cabinets de conseil ont rapidement réagi en annonçant des partenariats avec les leaders du secteur. Par exemple, le
BCG s'est associé à Anthropic pour promouvoir l'agent conversationnel Claude afin d'aider ses clients. McKinsey, de son côté,
a choisi Cohere comme partenaire pour ce type de services. Enfin,
le cabinet Bain a conclu une alliance avec OpenAI pour renforcer son offre de services liés aux intelligences artificielles génératives.
Mais les grands cabinets n'ont pas été les seuls à réagir. À une échelle plus modeste,
ClaraVista a également investi dans cette technologie. Elle mène des projets de recherche visant à explorer les capacités, les forces, les faiblesses et les différents cas d'utilisation potentiels de ces modèles. Dans cet article, nous vous présentons l'un de ces projets de recherche.
Contexte
Dans le cadre de notre exploration des outils d'IA générative, en particulier ceux capables de générer du texte en langage naturel, notre intérêt s'est porté sur l'automatisation des analyses quantitatives des données CRM, en se concentrant plus précisément sur la génération des "messages". Ces messages sont rédigés en langage naturel et décrivent les points forts et/ou marquants issus de diverses tables d'indicateurs que nous produisons pour nos analyses de profils clients.
En effet, lorsque nous produisons ce genre d’analyse, nous générons souvent de nombreuses tables, partageant une structure assez similaire pour la plupart. Chacune de ces tables doit être analysée par l'œil expert de nos analystes pour être synthétisées en quelques phrases (lesdits messages) décrivant les points forts et marquants présents dans cette dernière. Tout ceci forme donc un processus répétitif, chronophage mais indispensable, que l’on pourrait du coup grandement optimiser avec l’IA (du moins en théorie). Nous avons donc décidé de tester les capacités des modèles de langage les plus populaires, notamment les modèles GPT d'OpenAI, pour rédiger ces messages en analysant les données quantitatives présentes dans les tableaux de bord.
Pour évaluer la faisabilité de cette application, nous avons créé un ensemble de tableaux de bord marketing fictifs que nous avons soumis à l'analyse des IA. Ensuite, nous avons évalué la qualité des réponses fournies. Étant donné que nous contrôlions la génération de ces tableaux, nous y avons incorporé des phénomènes plus ou moins évidents, c'est-à-dire des indicateurs présentant des phénomènes marketing plus ou moins marqués, pour voir si les IA étaient en mesure de tirer les conclusions que nous souhaitions.
Dans la suite de cet article, nous commencerons par décrire la procédure expérimentale suivie, en décrivant les tableaux de bord fictifs que nous avons créés ainsi que le paramétrage des modèles utilisés lors des expérimentations. Ensuite, nous présenterons les analyses réalisées par les modèles GPT selon les différents scénarios détaillés dans la section précédente en examinant chaque observation générée, en nous assurant qu'elle est à la fois exacte et pertinente.
Enfin, nous précisons que toutes les réponses décrites dans cet article ont été obtenues via
l’API OpenAI et non pas via l’application
chatGPT. Les deux solutions sont sœurs dans leur fonction : elles permettent toutes les deux aux utilisateurs d'interagir avec les modèles de langages GPT d’OpenAI. Cependant, la première permet d’automatiser cette interaction, ce qui est plus pratique au vu de la quantité de
prompts que nous devions rédiger pour les besoins de l’étude. Elle permet aussi de contrôler plus facilement le paramétrage des modèles de langage. Ces deux facteurs font que nous avons préféré l’API à chatGPT. Cependant, nous pensons que les résultats présentés ci-après auraient été qualitativement semblables, car les modèles sous-jacents sont les mêmes.
Procédure expérimentale
| Remarques : |
| Dans cette section, nous allons dénoter le modèle GPT choisi par GPTx par commodité. En effet, les concepts et éléments décrits dans cette section s’appliquent de la même façon quelque soit la version du modèle GPT que l’on utilise. |
Lors de cette expérience, nous souhaitons évaluer la capacité de
GPTx à fournir les éléments suivants :
- Analyses qualitatives de données : à partir d’un ensemble d’indicateurs qu’on lui donne en entrée, on souhaite évaluer la capacité du modèle à fournir des analyses qualitatives de ces derniers et donc à écrire des messages pertinents.
- Recommandations stratégiques : à partir des données et/ou des messages, on souhaite évaluer si le modèle est capable de fournir des recommandations stratégiques pertinentes.
Ainsi, nous avons conçu un procédé où
GPTx doit fournir une analyse qualitative des données qu’il reçoit, complémentée d’un descriptif de ces données (pour lui fournir du contexte sur les indicateurs qu’il doit analyser). Ensuite, une fois sa réponse fournie, il doit fournir une recommandation stratégique,
à partir de sa propre réponse (i.e. son analyse qualitative) et d’informations de contexte à propos de l’entreprise et du secteur dans laquelle cette dernière opère. Ce procédé est décrit par le schéma suivant :
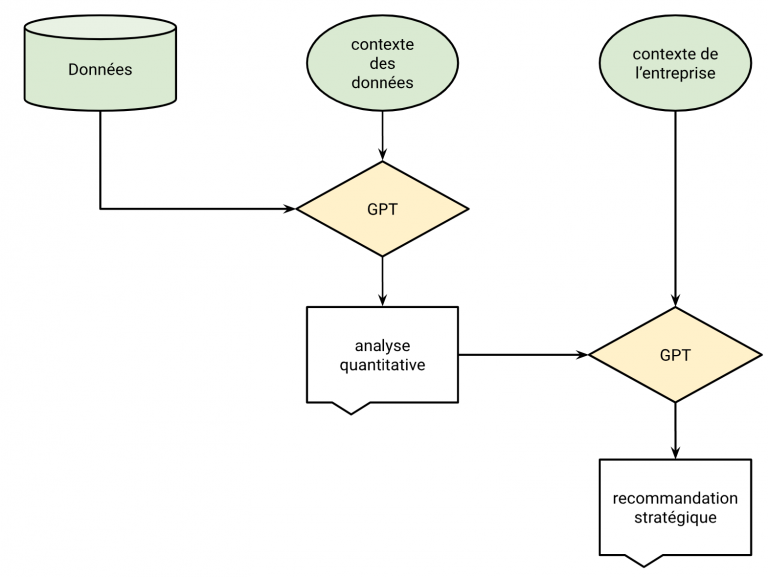
Ainsi, à partir d’un tableau de bord et d'informations de contexte sur ce dernier ainsi que l’entreprise pour laquelle il a été réalisé, nous allons procéder à une évaluation complète de la capacité de
GPTx à livrer des messages et des recommandations à l’entreprise qui a commandé le tableau de bord.
Ainsi, nous avons conçu plusieurs scénarios et avons construit les données en accord avec ce dernier. Chaque scénario représente une étude marketing fictive menée par une entreprise donnée sur plusieurs pays dans lesquels elle est représentée. En fonction des scénarios, les pays considérés par l’étude exhibent des performances différentes, que nous demandons à
GPTx de décrire (ce qui correspond à la partie “analyse quantitative” du schéma ci-dessus). Ensuite, nous demandons aux modèles de nous recommander un pays dans lequel l’entreprise devrait se renforcer (partie “recommandation stratégique” ci-dessus). Nous évaluons alors si
GPTx arrive à bien identifier les phénomènes insérés dans les données et donc à choisir le (ou l’un des) bon(s) pays dans lequel se renforcer.
Nous avons ensuite mis en œuvre une étape de
prompt engineering afin d’optimiser les requêtes (
prompts) correspondant aux deux questions décrites ci-dessus. Suite à cet étape, les deux requêtes sélectionnées sont présentées ci-après :
| 1. What are the insights you can derive from the provided data? Try to report only the noteworthy facts you observe, and provide a short answer (several lines top). |
| 2. Based on the observations and the global context, what is the best country in which a new store should be opened? |
Données
Afin de vérifier les dires de
GPTx, et donc vérifier si ce dernier est capable de fournir à la fois des analyses quantitatives et des recommandations stratégiques pertinentes, il est nécessaire de fournir une attention particulière aux données générées pour l’expérience. En effet, il est important de fournir des données représentant un phénomène précis et identifiable, afin de vérifier si
GPTx le détecte et s’il réagit correctement, i.e. en fournissant les bons messages et les bonnes recommandations.
Les tableaux de bords que nous avons généré pour cette expérience correspondent à des tables contenant un ensemble d’indicateurs classiques chez ClaraVista, décrivant le comportement d’achat d’une population de client, la démographie de la population, le recrutement (i.e. le comportement des nouveaux clients sur la période) et le réachat des clients formant la population. Ces indicateurs sont décrits dans la table suivante :
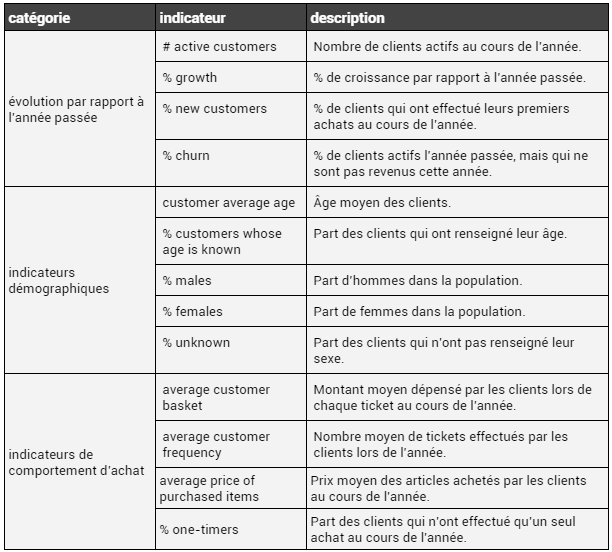
Ainsi, chaque scénario aura son propre tableau de bord, représenté par une table contenant des valeurs pour les indicateurs ci-dessus. Les valeurs seront donc choisies en fonction du scénario, pour refléter la situation décrite par ce dernier.
Un premier scénario simple : “luxury”
Dans ce scénario fictif, nous plongeons au cœur d'une entreprise spécialisée dans la vente de produits de luxe présente dans trois pays distincts : CountryA, CountryB et CountryC. Chacun de ces pays se caractérise par un niveau de développement bien distinct. CountryA se distingue par une clientèle aisée, qui effectue des achats fréquents et généreux. À l'inverse, CountryB abrite des clients moins fortunés, dont les achats sont plus modestes et moins fréquents. CountryC se situe quant à lui quelque part entre les deux extrêmes.
Pour évaluer ces pays, nous avons élaboré des indicateurs reflétant ces différences marquées. CountryA se distingue par des paniers moyens, des fréquences d'achat et des prix moyens très élevés. En revanche, CountryB affiche des indicateurs nettement plus bas, tandis que CountryC se situe dans une fourchette intermédiaire. Nous avons également supposé que les clients de CountryA sont en général plus âgés, car ils ont déjà établi leur situation financière. En dehors de ces spécificités, les autres indicateurs sont relativement similaires d'un pays à l'autre.
Dans cette analyse, nous attendons donc que
GPTx identifie les performances exceptionnelles de CountryA par rapport aux autres pays. En conséquence, nous nous attendons également à ce qu'il recommande l'ouverture d'un magasin dans CountryA.
Les indicateurs que nous allons fournir à
GPTx pour ce scénario sont donnés par la table suivante :
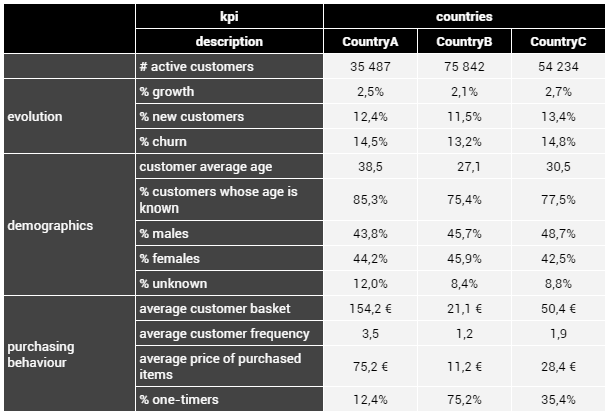
Les indicateurs ci-dessus indiquent donc bien un CountryA peuplé de clients plus fortunés, fréquents, âgés et renseignant plus leurs âges que les autres. En revanche, les autres indicateurs ne permettent pas de discriminer significativement les trois pays (exemple : le genre et le taux de croissance, de
churn et de recrutement).
Un deuxième scénario plus complexe : “geopolitics”
Dans ce scénario, nous nous aventurons dans des terres un peu plus exotiques, et nous considérons le cas d’une entreprise spécialisée dans la vente de potions de soins et d'onguents, opérant dans diverses régions de la
Terre du Milieu, le monde imaginaire créé par l'éminent écrivain J. R. R. Tolkien. Ces régions incluent le Gondor, le Rohan, le Mordor et la Comté. Nous posons l'hypothèse que cette entreprise a établi sa présence à la fois parmi les Humains (au Gondor et au Rohan), les Orcs (au Mordor) et les Hobbits (à la Comté), et que toutes ces factions sont ouvertes au commerce avec elle.
Nous considérons également la situation où le Rohan et le Mordor sont engagés dans un conflit armé, tandis que le Gondor demeure neutre. Il est important de noter que le Gondor maintient des liens diplomatiques avec le Rohan, ce qui pourrait le conduire à se joindre à ce dernier dans son conflit contre le Mordor à l'avenir. Enfin, nous supposons que la Comté adopte une politique d'isolement strict et ne prendra pas part au conflit de quelque manière que ce soit.
En ce qui concerne les indicateurs, nous définissons ces derniers de manière à représenter le Gondor comme étant plus prospère que les autres pays, avec une clientèle plus aisée qui a tendance à effectuer des achats plus coûteux. Cependant, à l'instar de la Comté, les clients du Gondor achètent rarement, car le pays est en paix et ils n'ont donc que rarement besoin de produits de soins. En ce qui concerne le Mordor et le Rohan, la guerre incite les clients à acheter fréquemment, mais les clients du Mordor sont moins fortunés, bien que plus nombreux que ceux du Rohan. Ils dépensent donc moins et optent pour des produits moins onéreux. Enfin, nous définissons des taux de désengagement et de recrutement standards pour le Gondor, le Rohan et la Comté, mais des taux respectivement très bas et très élevés pour le Mordor, suggérant ainsi un fort enthousiasme et une grande fidélité de la part de ses clients.
En termes de recommandation, nous anticipons donc que
GPTx suggère de renforcer la présence soit au Gondor soit au Mordor. L'argument avancé serait que les clients du Gondor sont aisés, offrant ainsi un potentiel de développement de la marque, mais que le Mordor présente un engouement plus marqué, avec une clientèle plus nombreuse, ce qui représente également un excellent potentiel de rentabilité.
Les indicateurs correspondant à ce scénario sont présentés ci-après :
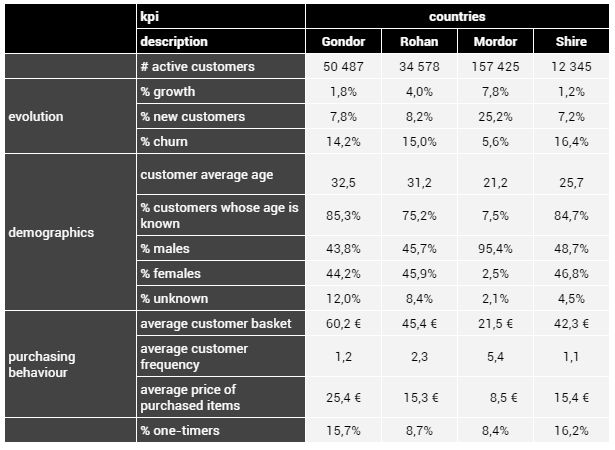
Les indicateurs précédents reflètent clairement la situation évoquée :
- Le Gondor possède une clientèle dépensière qui semble avoir une préférence pour les produits de luxe. Toutefois, la croissance de la marque y est modeste, et les taux de recrutement et de désengagement sont similaires à ceux observés au Rohan et dans la Comté.
- Quant à la Comté, elle compte une clientèle plutôt standard, sans caractéristiques particulières, et correspondant à un pays neutre relativement isolé du conflit.
- Le Mordor, en guerre contre le Rohan, attire une clientèle plutôt modeste en termes de dépenses (panier moyen et prix par article bas), mais cette clientèle se montre loyale : elle revient fréquemment, effectue des achats réguliers et reste engagée. De plus, nous avons conçu ce marché de manière à refléter une expansion notable, avec un taux de recrutement élevé et une croissance nettement supérieure à celle des autres régions.
- Le Rohan, également en guerre, compte une clientèle plus aisée que celle du Mordor, présentant des caractéristiques démographiques similaires à celles du Gondor mais avec des ressources moindres. Toutefois, en raison du conflit, ses clients effectuent des achats plus fréquents et répétés que dans les pays encore neutres (Gondor et Comté). Enfin, le marché du Rohan ressemble à celui des deux pays neutres en termes de taux de recrutement et de désengagement, à l'exception d'une croissance plus marquée, également due au conflit en cours avec le Mordor.
Paramètres de l’expérience
Dans l'ensemble de nos expérimentations, nous avons configuré
GPTx avec une température de 0, ce qui le contraint à toujours sélectionner le mot le plus probable lors de la génération de texte. Cette approche vise à limiter les éventuelles erreurs factuelles dans les analyses qualitatives de ce dernier, qui pourraient survenir s'il était autorisé à choisir des mots moins probables (ce qui serait le cas avec une température non nulle). Pour une compréhension approfondie du concept de température dans le contexte d'un agent conversationnel, nous vous invitons à consulter
l'excellent article de NVIDIA qui détaille les paramètres couramment utilisés lors de l'exploitation de modèles de langage tels que les modèles GPTx.
De plus, nous avons fixé la longueur maximale des réponses à 1024 tokens, ce qui permet à
GPTx de fournir des réponses complètes sans être tronqué. Tous les autres paramètres non explicités dans cette section sont laissés à leurs valeurs par défaut.
Enfin, lors de l'analyse des réponses de GPTx aux deux questions décrites dans la section
"Procédure expérimentale", nous avons adopté une coloration systématique des passages en fonction de leur exactitude : vert pour les affirmations correctes, rouge pour les inexactitudes, et jaune pour les éléments discutables ou non pertinents, sans nécessairement être incorrects.
Expérience 1 - GPT3.5
Après avoir décrit avec attention la procédure expérimentale dans la section
Procédure expérimentale, nous pouvons enfin passer aux résultats.
Dans cette première expérience, nous allons évaluer le modèle
GPT3.5, i.e. le premier agent conversationnel publié par OpenAI via leur application chatGPT. Ainsi, ce sera ce modèle qui alimentera les réponses de
GPT3.5 et qui effectuera les raisonnements nécessaires pour tous les scénarios décrits dans
Procédure expérimentale. Le modèle
GPT4, successeur de GPT3.5, sera évalué dans la section
Expérience 2 - GPT4.
GPT3.5 - scénario "luxury"
Commençons par présenter les résultats de
GPT3.5 sur le premier scénario, "luxury", décrit à la section
Un premier scénario simple : "luxury". Nous présentons ci-dessous la réponse de
GPT3.5 à la première question (référez-vous au tableau de la section mentionnée précédemment pour connaître les valeurs) :
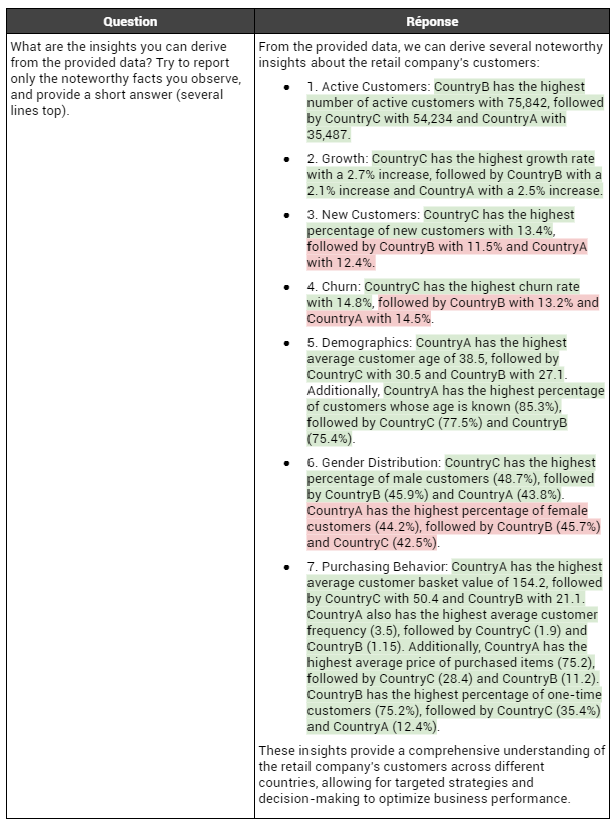
Nous remarquons tout d’abord que
GPT3.5 fournit un compte-rendu détaillé et verbeux de la table de données qui lui a été présentée. En effet, tous les indicateurs présents dans la table se retrouvent dans le descriptif (sauf pour le % de client dont le genre est inconnu, qui s’obtient avec les deux autres %). Cependant, nous remarquons qu’il se trompe plusieurs fois (3 fois sur les 12 classements effectués) dans le classement des valeurs, en intervertissant les ordres. Néanmoins, toutes les valeurs sont correctement assignées à leurs pays. Enfin, on constate que
GPT3.5 ne tire aucune conclusion des observations qu’il effectue.
Cependant, ceci pourra être utile pour la seconde question qui, rappelons-le, est obtenue en envoyant les analyses de
GPT3.5 en entrée et non pas directement les indicateurs. En effet, de cette façon,
GPT3.5 pourra raisonner sur du contenu verbeux uniquement lorsqu’il s’agira de fournir des recommandations, ce qui pourra peut-être améliorer ses capacités de raisonnement. La réponse qu’il a fourni est présentée ci-après :
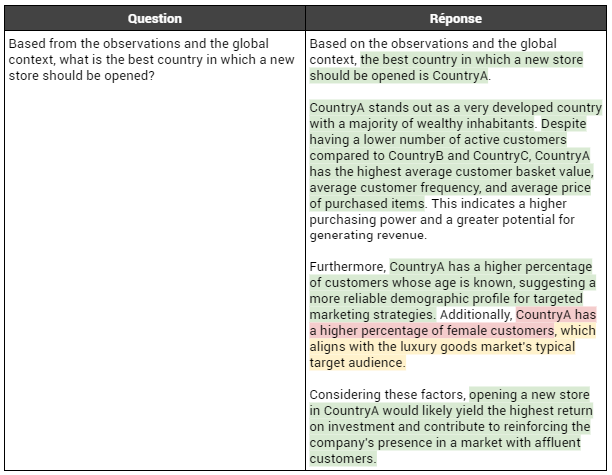
La chose la plus importante à observer est que
GPT3.5 arrive au constat voulu, i.e. qu’il faut renforcer la présence de la marque au CountryA. En effet, il justifie cette décision par le bon argument : les clients du CountryA sont plus riches que ceux des deux autres pays et présentent des indicateurs de comportement d’achats plus favorables. On remarque aussi qu’il effectue la corrélation entre le taux de remplissage de l’âge et la bonne réponse aux campagnes marketing ciblées, ce qui est très pertinent.
On remarque cependant une analyse étonnante de
GPT3.5 qui semble corréler les produits de luxe aux clients féminins. Nous ne savons pas si cette corrélation est généralement observée dans le luxe, mais elle semble tout de même hasardeuse sans plus d’information sur la nature des produits (on peut penser aux montres Rolex par exemple, qui sont un produit de luxe mais sont,
a priori, plus adressées aux hommes qu’aux femmes).
Enfin, nous observons de nouveau la mauvaise observation sur CountryA disposant selon
GPT3.5 du plus grand taux de clients féminins (ce qui est faux, c’est CountryB), mais ceci s’explique par le fait que
GPT3.5 ne disposait que de ses propres observations pour cette question, et qu’il est donc attendu que les erreurs commises à la première étape se propagent à la seconde.
Pour conclure, bien que
GPT3.5 ait fait plusieurs erreurs sur l’analyse de certains indicateurs, il arrive à la bonne conclusion et justifie correctement cette dernière.
GPT3.5 - scénario "geopolitics"
Nous passons désormais au scénario "geopolitics", représentant un monde en guerre dans lequel un fabricant de produits médicaux tente de tirer son épingle du jeu (cf la section
Un deuxième scénario plus complexe : "geopolitics"). Voici ce que remarque
GPT3.5 face à ces indicateurs :
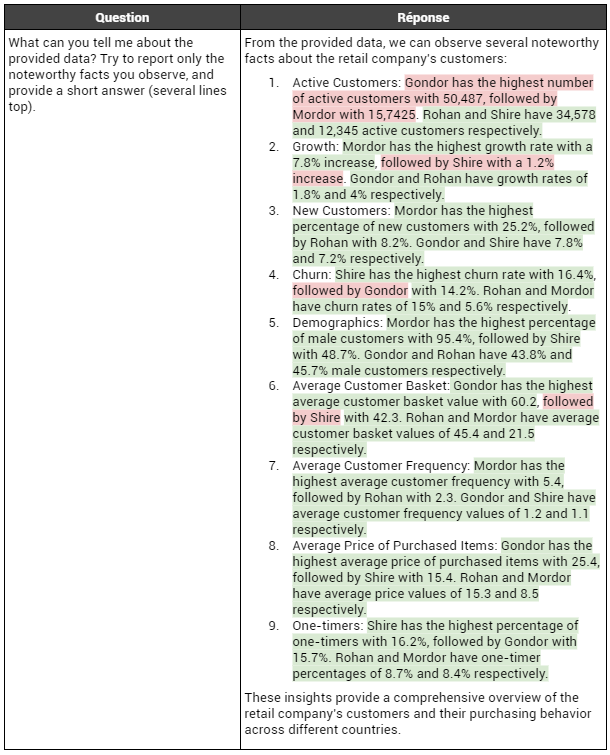
Encore une fois, on observe un comportement similaire de
GPT3.5 par rapport à la section
Scénario "luxury" : il remarque bien la plupart des faits décrits par les indicateurs, mais se trompe de temps en temps sur les ordres de grandeur ou les classements. Dans ce cas, il se trompe tout de même sur un fait important, en plaçant le Gondor en première position en termes de base de clients actifs, alors que le Mordor est bien au-dessus. L’erreur est plus sérieuse que ça qui plus est, car il se trompe dans la position de la virgule, qu’il déplace d’un cran à gauche, ce qui peut laisser croire que le Mordor a environ 15k clients alors qu’il en a 157k. Cependant, comme pour le cas "luxury", ces erreurs ne changent (pour la plupart) pas qualitativement les observations car le premier est presque toujours bon (sauf pour la base de clients actifs).
Passons maintenant à la seconde question, et observons quelles seront les conséquences des erreurs commises par
GPT3.5 lors de la première étape. En effet, on rappelle que pour la seconde question, ce dernier dispose de ses propres observations & analyses, et non pas des données tabulaires. La réponse de
GPT3.5 à la seconde question est fournie ci-après :
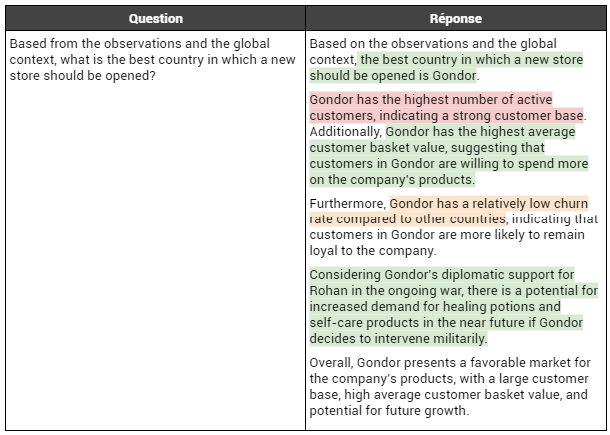
Une fois de plus, nous constatons que GPT3.5 parvient à tirer une conclusion pertinente en suggérant l'ouverture d'un nouveau magasin au Gondor. De plus, il avance des arguments solides à cet égard : il note que les clients du Gondor sont plus enclins à dépenser dans les magasins et prêts à payer davantage pour leurs produits. Cependant, l'aspect le plus intrigant de la réponse de GPT3.5 réside dans sa capacité à intégrer correctement le contexte diplomatique qui lui a été fourni. En effet, il prend en compte le fait que le Gondor est un allié diplomatique de Rohan et qu'il pourrait se joindre au conflit. GPT3.5 note également que l'entrée en guerre du Gondor devrait entraîner une augmentation de la fidélité des clients, étant donné que l'entreprise vend des produits médicaux. Cette prise en compte du contexte est cruciale, car elle démontre la capacité de GPT3.5 à croiser des informations contextuelles et des observations qualitatives pour étayer ses recommandations.
Cependant, certaines erreurs persistantes subsistent par rapport à la première question. GPT3.5 réitère, à tort, que le Gondor a la plus grande base de clients actifs, alors que c'est le Mordor qui détient cette position. Ceci est attendu, vu qu’il n’a connaissance que de ses observations, qui sont erronées sur ce fait. De plus, il note que le Gondor a un taux de désengagement (
churn) relativement faible par rapport aux autres pays, ce qui n'est pas tout à fait exact : son taux est en effet légèrement inférieur à celui de Rohan et de la Comté, mais nettement supérieur à celui du Mordor. Ces deux éléments, incorrectement pris en compte par GPT3.5 et favorables au Gondor par rapport au Mordor, expliquent pourquoi le modèle ne songe pas à ouvrir une boutique au Mordor, même si cela aurait pu être une autre option à envisager. En effet, bien que les clients du Mordor disposent de moins de ressources financières, ils font preuve d'une plus grande fidélité et fréquentent plus assidûment les magasins. De plus, la croissance est significativement plus forte au Mordor. Ces deux facteurs auraient pu faire du Mordor un choix judicieux, mais GPT3.5 ne l'a pas mentionné.
GPT3.5 - Conclusion
Ainsi, nous avons examiné attentivement les analyses quantitatives et les recommandations générées par GPT3.5 lors de l'analyse des tableaux de bord pour les deux scénarios, "luxury" et "geopolitics". Cette analyse nous a fourni des informations précieuses.
Tout d'abord, nous avons constaté que GPT3.5 est capable d'interpréter des tableaux de données lorsqu'ils sont présentés en langage naturel, ce qui constitue déjà une réalisation significative en soi. De plus, nous avons remarqué que GPT3.5 parvient à interpréter correctement la grande majorité des informations contenues dans les tableaux qui lui sont soumis, démontrant ainsi une solide compréhension des concepts marketing. Enfin, toutes les réponses générées par GPT3.5 sont structurées, argumentées et rédigées de manière claire et professionnelle. À première vue, il semble donc avoir le potentiel pour être un analyste marketing exceptionnel.
Cependant, un examen plus approfondi de ces réponses a révélé certaines erreurs qui peuvent être attribuées sans équivoque à des "hallucinations" du modèle (un phénomène couramment observé dans les grands modèles de langage de type GPT) :
- Dans le scénario "luxury", GPT3.5 peut parfois se tromper dans le classement des pays en plaçant l'un devant l'autre sur un indicateur, même si les valeurs indiquent clairement le contraire.
- Dans le scénario "geopolitics", GPT3.5 peut également commettre des erreurs en plaçant incorrectement la virgule, entraînant ainsi une interprétation erronée de la valeur.
Par conséquent, bien que GPT3.5 n'ait pas émis de recommandations erronées dans le cadre de nos expériences, il est important de reconnaître que l'utilisation de ce modèle dans un environnement de production, avec une série de tableaux de bord, comporte le risque qu'une de ses "hallucinations" puisse éventuellement biaiser son raisonnement et conduire à des recommandations incorrectes, basées sur des données ou des interprétations inexactes. Par conséquent, il est essentiel de maintenir la participation humaine dans le processus de décision et de faire appel à un expert du secteur pour vérifier les conclusions, afin de détecter d'éventuelles erreurs.
Enfin, la question se pose : si GPT3.5 commet des erreurs, serait-ce le cas de son successeur, GPT4, qui est censé être plus puissant ? Après tout,
GPT4 serait conçu comme une collaboration entre 8 GPT3.5 spécialisés, et l'un d'entre eux pourrait être axé sur l'analyse des tableaux, ce qui réduirait le risque d'erreurs. Cette hypothèse mérite d'être explorée davantage !
Expérience 2 - GPT4
Nous allons dans cette section tenter de corriger les erreurs observées
avec GPT3.5 en améliorant le modèle sous-jacent avec
GPT4, le successeur de GPT3.5, dix fois plus cher que ce dernier, mais censé être bien plus puissant et fiable. Tous les autres paramètres sont inchangés par rapport à la section
Paramètres de l’expérience.
GPT4 - scénario "luxury"
Commençons de nouveau par le scénario "luxury", où CountryA présente tous les avantages pour ouvrir un nouveau magasin par rapport aux deux autres pays CountryB (pauvre) et CountryC (moyen). La réponse fournie à la première question est présentée ci-dessous :
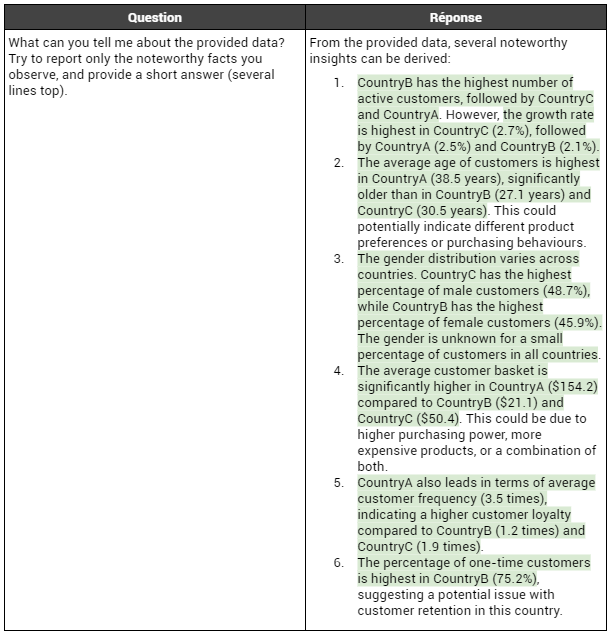
Un premier constat qui se dégage est que GPT4 présente une amélioration notable par rapport à GPT3.5 dans l'analyse des données, en effectuant systématiquement des classements corrects des pays en fonction des différents indicateurs. Contrairement à GPT3.5, qui pouvait occasionnellement se tromper, comme illustré dans la section
Scénario "luxury". De plus, GPT4 semble prendre en considération l'ordre de grandeur des variations entre les valeurs des pays, en distinguant les différences importantes des plus modestes. Enfin, GPT4 arrive à remarquer tous les phénomènes que nous avons intégrés dans les données.
Voyons voir si la recommandation fournie change avec ces nouvelles observations, plus justes que celles de GPT3.5 :
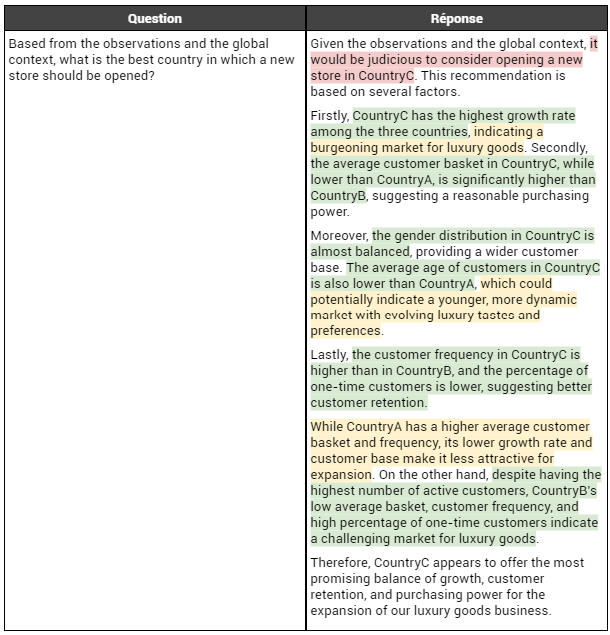
Nous constatons avec étonnement que GPT4 préconise de renforcer la présence de la marque dans CountryC (le pays "moyen"), plutôt que dans CountryA (le pays riche) comme l'avait fait GPT3.5. Cette recommandation s'appuie principalement sur deux arguments : un marché plus favorable que celui de CountryB (le pays pauvre) et une croissance plus importante que celle observée pour CountryA. Si le premier argument est incontestable, le second ne l’est pas, car la différence en termes de croissance entre CountryA et CountryC est modeste. Ce qui interpelle, c'est que GPT4 reconnaît que les clients de CountryA affichent de meilleures performances, mais cela ne suffit pas à le faire pencher en faveur de ce dernier par rapport à CountryC. Ainsi, si les arguments avancés par GPT4 sont pertinents, il semble néanmoins commettre une légère erreur de raisonnement, en accordant une importance excessive à certains éléments (notamment la croissance), ce qui altère sa recommandation.
Cette erreur dans la recommandation est d'autant plus surprenante que GPT4 avait excellé dans ses interprétations précédentes et semblait plus pertinent dans ses analyses que GPT3.5. Si nous nous aventurons à tenter d'expliquer cette situation, nous pourrions avancer l'idée que la recommandation de CountryC (au lieu de CountryA) est en réalité une erreur commise par GPT4 sur ce mot en particulier. Ensuite, étant donné que les modèles GPT sont des modèles génératifs, GPT4 a dû générer les mots suivants avec cette erreur déjà présente, qu'il ne pouvait plus corriger. Il a donc tenté de justifier ce mauvais choix comme il le pouvait, en avançant une série d'arguments qui ne sont pas tout à fait faux, mais qui ne sont pas non plus tout à fait justes (surlignés en jaune dans le tableau ci-dessus).
GPT4 - scénario "geopolitics"
Afin de savoir si le passage à GPT4, censé être plus performant que GPT3.5, permet de corriger ou du moins de diminuer les erreurs effectuées lors de la description des données (étape 1 de la section
Procédure expérimentale), nous avons réalisé le scénario "geopolitics" en utilisant GPT4 au lieu de GPT3.5. Les autres paramètres ont été inchangés.
La réponse apportée à la première question est présentée ci-dessous :
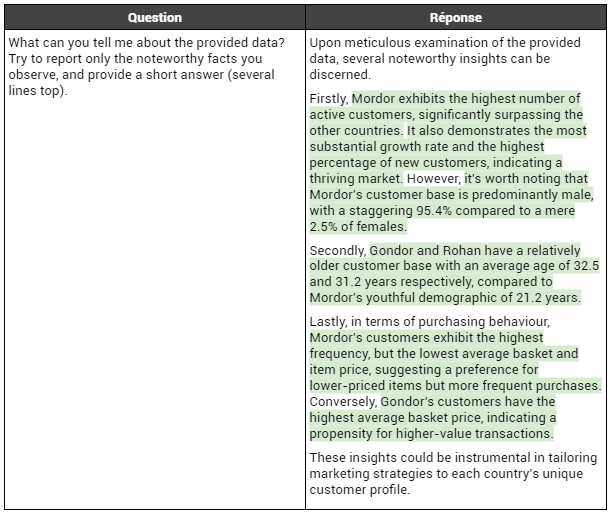
Nous observons que, de nouveau, GPT4 ne commet aucune erreur d’analyse : toutes les observations décrites sont correctes, et GPT4 semble à nouveau prendre en compte les ordres de grandeur. En effet, il observe que la proportion d’hommes parmi la clientèle du Mordor est étonnamment élevée par rapport aux autres pays. Il remarque également que le Mordor a significativement plus de clients actifs que les autres. Ceci est une nette amélioration qualitative par rapport aux observations faites avec GPT3.5, qui semblait se contenter de faire des classements.
Voyons voir si la recommandation fournie pour la seconde question change par rapport à celle de la section
Scénario "geopolitics":
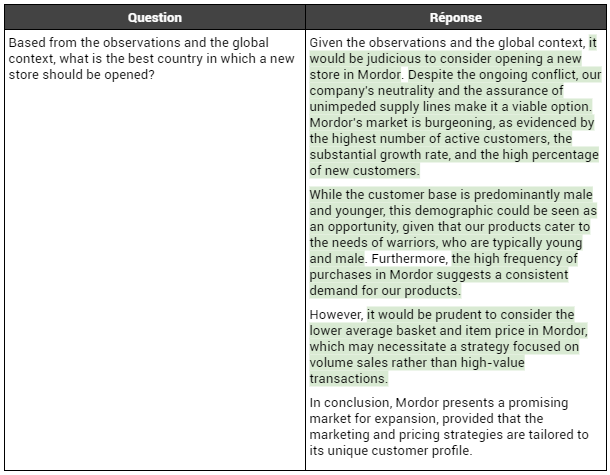
Nous constatons que GPT4 préconise désormais de renforcer sa présence au Mordor, en contraste avec son prédécesseur qui suggérait plutôt le Gondor. Cette recommandation est étayée par des faits avérés : le Mordor affiche une clientèle plus importante et un marché en pleine expansion, ce qui en fait une opportunité favorable pour l'ouverture d'un nouveau magasin. Cependant, il nuance judicieusement sa recommandation en mettant en évidence le budget moyen relativement faible des clients du Mordor, suggérant ainsi une adaptation de la stratégie marketing.
Par ailleurs, nous notons une fois de plus que GPT4 tient compte du contexte dans sa proposition. Il souligne notamment que la position de l'entreprise permet d'envisager sereinement des activités au Mordor, en raison de la neutralité de l'entreprise, et que l'assurance d'un approvisionnement stable malgré le conflit rend viable l'option d'ouvrir un magasin dans cette région. De plus, il intègre le contexte en mentionnant que la clientèle du Mordor est majoritairement jeune et masculine, ce qui correspond à la cible des produits de l'entreprise, essentiellement des produits de soin destinés aux soldats, qui sont souvent jeunes et masculins.
En conclusion, nous observons que, pour ce scénario, les observations et recommandations effectuées par GPT4 sont qualitativement meilleures que celles fournies par GPT3.5.
GPT4 - Conclusion
En résumé, GPT4 semble démontrer une capacité supérieure à celle de son prédécesseur, GPT3.5, en tant qu'analyste marketing compétent. Il se distingue en évitant toute erreur dans la manipulation de données et dans la classification lors de ses analyses. De plus, il semble prendre en considération l'ordre de grandeur lorsqu'il examine les tableaux de bord, une compétence qui manquait à GPT3.5. De surcroît, il est capable de fournir des recommandations pertinentes et bien argumentées, en prenant soin de prendre en compte le contexte (par exemple, en suggérant d'adapter la stratégie marketing pour les clients moins fortunés de Mordor dans
le scénario "géopolitique").
Cependant, de manière paradoxale, malgré ces interprétations brillantes et pertinentes, nous avons constaté une recommandation erronée dans
le scénario "luxury". En effet, GPT4 a recommandé le mauvais pays, et a ensuite tenté de se justifier en utilisant une série d'arguments plutôt hasardeux, qui pourraient être considérés comme de la mauvaise foi s'ils avaient été formulés par un analyste humain. Nous attribuons ce phénomène à une unique hallucination survenue à un moment critique, poussant GPT4 à élaborer un argumentaire pour tenter de pallier cette erreur irréparable.
Cette seule erreur remet en question l'utilisation non supervisée de GPT4 en tant qu'analyste marketing. Par conséquent, tout comme son prédécesseur, ses réponses nécessitent une relecture et une validation par un expert afin de prévenir toute recommandation basée sur des hallucinations.
Conclusion
Ainsi, au cours de cette étude, nous avons scruté l'aptitude des modèles GPT d'OpenAI à automatiser l'analyse des tableaux de bord et la rédaction de rapports correspondants. Pour ce faire, nous avons créé des tableaux de bord fictifs contenant des indicateurs bien établis, en évitant délibérément nos indicateurs plus avancés et moins intuitifs. Ces tableaux de bord décrivaient des situations spécifiques, détaillées dans la section
Procédure expérimentale, et variaient en termes de facilité d'interprétation à partir des valeurs des indicateurs. Nous avons ensuite vérifié si les modèles étaient capables de fournir les analyses et les recommandations attendues.
Dans
la première expérience, nous avons évalué les capacités de GPT3.5, le modèle qui alimente la version gratuite de chatGPT, pour générer des analyses et des observations à partir des tableaux d'indicateurs. Nous avons constaté que GPT3.5 était généralement capable de fournir des observations correctes (c'est-à-dire la description des valeurs des indicateurs) mais qu'il commettait régulièrement des erreurs de classification des valeurs des indicateurs. De plus, il semblait avoir du mal à saisir l'ordre de grandeur des différences observées, en traitant par exemple de la même manière une différence du simple au double et une différence à la virgule près. Malgré ces limitations, dans les deux scénarios étudiés, GPT3.5 a abouti à la conclusion correcte et a fourni l'une des recommandations attendues. En d'autres termes, ses erreurs d'observation n'ont pas influencé le résultat final. Cependant, compte tenu de la nature des erreurs possibles, il est plausible, voire certain en cas de répétition, qu'une erreur puisse se produire sur un aspect crucial, poussant ainsi GPT3.5 à une recommandation incorrecte. Par conséquent, GPT3.5 semble encore insuffisamment fiable pour mener à bien la tâche et nécessite une intervention humaine tout au long du processus.
Dans
une seconde expérience, nous avons reproduit le processus en utilisant GPT4, le successeur de GPT3.5. Cette fois-ci, nous avons remarqué que ce premier semblait ne plus faire d'erreurs de classification et qu'il était capable de discerner les écarts significatifs des écarts mineurs entre les indicateurs. Ainsi, GPT4 semble corriger les erreurs commises par GPT3.5 dans la rédaction des analyses. Cependant, de manière paradoxale, malgré ses interprétations justes, nous avons observé que GPT4 s'est trompé dans l'une des deux situations (
le scénario "luxury"). En effet, il a confondu deux pays au début de sa recommandation (erreur similaire à celle de GPT3.5), puis a cherché à justifier sa recommandation erronée en utilisant une série d’arguments biaisés à défaut d’être incorrects. Ce comportement est potentiellement problématique, car il peut compliquer la détection des erreurs. Ainsi, bien que très impressionnant, GPT4 requiert également une intervention humaine dès l'analyse des données, tout comme son prédécesseur.
Nous constatons donc que, bien que les modèles proposés par OpenAI soient impressionnants et hautement performants, ils ne sont pas encore prêts à fonctionner de manière autonome et nécessitent une guidance humaine tout au long du processus. Cependant, leur utilisation en tandem avec l'expertise humaine peut grandement améliorer la qualité des résultats, car les experts peuvent tirer parti de leurs capacités rédactionnelles et de leur exhaustivité pour créer des rapports plus complets, plus fiables et mieux argumentés. Cette collaboration entre l'intelligence artificielle et l'intelligence humaine est un principe que ClaraVista soutient depuis de nombreuses années et que nous préconisons auprès de nos clients, l'appliquant dans tous nos projets. En combinant la puissance de l'apprentissage automatique (englobant les IA de type GPT) et l'expertise en marketing, nous sommes convaincus d'atteindre les meilleurs résultats, et cette étude vient renforcer cette conviction.
Si vous souhaitez en savoir plus sur nos travaux ou pensez que notre expertise pourrait vous être bénéfique, n'hésitez pas à nous contacter via
notre site web.
www.claravista.ai