Publié le 26 juin 2025 à 09:06
Ahmed-Amine HOMMAN, PhD, Research Project Manager
En quelques années à peine (depuis 2022 et la sortie de ChatGPT), les grands modèles de langage (Large Language Models, LLMs, en anglais) sont passés du statut de curiosité technique à celui de compagnons de discussion au quotidien. Mais que se cache-t-il derrière ces agents capables de dialoguer avec cohérence, humour ou précision ? Comment une simple machine, à l’origine conçue pour compléter du texte, en est-elle venue à mener des conversations, raisonner étape par étape, ou même interagir avec des outils ?
Dans notre précédent article, nous avons posé les bases de l’intelligence artificielle dite générative, en explorant les trois grandes familles de modèles qui la composent : les grands modèles de langage (Large Language Models ou LLMs), capables de produire du texte ; les diffuseurs, qui génèrent des images ou des vidéos ; et les encodeurs, qui transforment du texte ou des images en représentations vectorielles. Nous avons également mis en lumière l’architecture Transformer, présentée en 2017 dans l’article fondateur Attention Is All You Need, qui constitue le socle commun de ces modèles. Cette architecture, en remplaçant les mécanismes séquentiels par une approche basée uniquement sur l’attention, a permis des avancées majeures en termes de performance et de parallélisation, ouvrant la voie aux développements actuels de l’IA générative.
Dans cet article, nous allons nous concentrer sur le premier type de modèle, les LLMs, et allons remonter à la source. Vous découvrirez comment fonctionnent les LLMs, depuis leur apprentissage fondamental jusqu’aux raffinements qui les transforment en véritables agents conversationnels.
Portée de cet article : dans cet article, nous allons adopter une démarche de vulgarisation : l’objectif est de fournir une intuition claire du fonctionnement des LLMs, sans entrer dans tous les détails mathématiques ou techniques. Certaines explications seront donc volontairement simplifiées, et ne couvriront pas les nombreuses optimisations ou variantes propres à chaque modèle. Il ne s’agit pas d’un cours d’algorithmique, mais d’un aperçu général fidèle à l’esprit de ces technologies, et accessible sans bagage technique avancé.
Avant de parler d'agents intelligents ou de capacités conversationnelles, il faut revenir à l’essentiel : ce que sait faire un LLM, fondamentalement. À la base, ces modèles ne font qu’une chose – mais ils le font remarquablement bien : compléter du texte.
Dans cette section, nous allons explorer ce mécanisme de complétion, voir comment il est rendu possible par la représentation du langage en tokens, et comprendre comment un modèle apprend à prédire ce qui vient ensuite. C’est ce socle, apparemment simple, qui permet ensuite tous les raffinements que nous verrons plus tard.
Au cœur du fonctionnement des LLMs réside un mécanisme fondamental : la prédiction du token suivant. Imaginez le token comme la plus petite brique de langage que le modèle manipule. Il peut s'agir d'un mot complet, d'un fragment de mot, voire d'un simple caractère (nous plongerons plus en détail dans cette notion cruciale un peu plus loin). Pour simplifier notre approche dans un premier temps, et pour des besoins de clarté, considérons que ces tokens correspondent aux mots de notre vocabulaire usuel. Sous cette hypothèse, on peut donc voir les LLMs comme de performants outils d'auto-complétion, dont la tâche principale est d'anticiper le mot qui suit dans une séquence textuelle donnée.
Prenons un exemple concret : si l’on fournit au modèle le début de texte « Toc Toc. », il y a fort à parier qu’il proposera « Qui » avec une très forte probabilité. En effet, cette amorce est typique d’une blague bien connue, et le modèle aura appris cette association durant son entraînement. En revanche, un mot comme « réfrigérateur » aura une probabilité bien plus faible, car il n’a aucun lien logique avec le contexte.
Pour générer du texte, il suffit de suivre cette logique :
Ainsi, à partir de « Toc Toc. », le modèle prédit « Qui », puis « est », puis « là », jusqu’à reconstituer la phrase « Qui est là ? ». C’est en empilant ces petites prédictions que l’on obtient un texte fluide et cohérent.
Mais comment choisir le prochain mot ? Une méthode consiste à prendre celui qui a la probabilité la plus élevée. Ce choix garantit souvent une réponse logique, mais il peut rendre le texte prévisible, voire fade. Pour introduire de la variété, on peut aussi tirer aléatoirement un mot selon la distribution calculée par le modèle. Cela permet d'explorer des chemins moins évidents, parfois plus créatifs ou naturels.
On comprend alors qu’un « bon » LLM est un modèle capable d’attribuer des probabilités justes aux mots, en fonction du contexte. S’il se trompe, les mots prédits seront inadaptés, et le texte perdra toute cohérence. En revanche, un modèle bien entraîné saura choisir des mots qui s’enchaînent naturellement, donnant naissance à une production textuelle fluide et pertinente.
Nous avons parlé de « mots » dans la section précédente afin de faciliter la compréhension. Mais pour un modèle de langage, ce n’est pas si simple. Les LLMs ne travaillent pas directement avec des mots entiers, mais avec des unités plus fines appelées tokens.
Un token, c’est une portion de texte : parfois un mot entier, mais souvent une partie de mot, un suffixe, une racine, ou même un simple caractère. Pourquoi ce découpage ? Pour rendre le langage plus maniable, et surtout plus souple.
Le mot « manger » illustre bien cela. Il se décline en de multiples formes : mange, mangent, mangeaient, mangeoire, et ainsi de suite. Imaginez la taille du vocabulaire nécessaire si le modèle devait enregistrer chaque variation séparément ! L'astuce des tokens est de réduire ce fardeau. Le modèle apprend un ensemble limité d'unités de base, comme “mange”, “nt”, “aient”, “oire”, et peut ensuite les assembler pour reconstruire les mots complexes : “mangent” devient “mange” + “nt”, “mangeaient” équivaut à “mange” + “aient”, etc. Cette méthode maline renforce la robustesse du modèle face aux erreurs de frappe, aux mots nouveaux ou rares, car il s'appuie sur des éléments constitutifs qu'il connaît déjà.
En pratique, c’est un outil appelé tokenizer qui se charge de ce découpage. Il transforme une phrase en une séquence de tokens, en s’appuyant sur un vocabulaire prédéfini appris lors de son propre entraînement. Ce vocabulaire contient typiquement quelques dizaines de milliers d’unités : suffisamment pour couvrir les constructions les plus fréquentes d’une langue, mais pas assez pour inclure tous les mots existants. C’est pourquoi certains mots rares ou nouveaux sont découpés en fragments plus petits, parfois jusqu’au caractère isolé. Ce découpage n’est pas arbitraire : il suit des règles statistiques conçues pour maximiser la couverture du langage tout en limitant la taille du vocabulaire. Même les signes de ponctuation, les espaces ou les symboles spéciaux peuvent constituer des tokens à part entière. Le résultat final est une représentation compacte et standardisée du texte, que le modèle de langage pourra ensuite traiter.
Pour approfondir : Pour ceux qui souhaitent aller plus loin, les principaux tokenizers des LLMs les plus répandus s’appuient sur l’algorithme Byte Pair Encoding (BPE), conceptualisé par Philip Gage en 1994. Initialement une technique de compression de données, cet algorithme a été adapté en 2015 par Sennrich et al. pour être utilisé dans les réseaux de neurones profonds tels que les LLMs.
Reprenons notre amorce “Toc Toc.”, suivie de la célèbre réplique “ Qui est là ?”. Avec le tokenizer utilisé par les modèles d’OpenAI (appelé tiktoken), cette phrase ne sera pas découpée en mots, mais en unités plus fines : ["_Qui", "_est", "_là", "_?"]. Ici, le caractère “_” symbolise un espace insécable placé avant le mot. Cela signifie que “Qui” et “_Qui” sont deux tokens différents, et que le modèle les traite comme tels. Cette subtilité permet au modèle de mieux gérer la ponctuation, les espacements, et les contextes linguistiques. Ainsi, même une courte phrase peut nécessiter plusieurs tokens pour être générée.
Ce découpage permet de mieux équilibrer taille du vocabulaire, coût de calcul et flexibilité. Plus les tokens sont courts, plus il faudra d’étapes pour générer un texte — mais le modèle sera aussi plus agile pour composer des mots nouveaux. Plus les tokens sont longs, moins il faudra d’étapes pour générer un texte mais plus le vocabulaire sera grand, et l’empreinte mémoire du calcul avec.
C’est ce jeu subtil entre découpage, expressivité et efficacité qui constitue l’un des fondements des LLMs modernes.
Nous avons vu qu’un LLM cherche à compléter un texte donné en prédisant le prochain token le plus probable. Mais comment devient-il capable de le faire de manière cohérente ? C’est là qu’intervient une étape essentielle : le pré-entraînement.
Le pré-entraînement consiste à exposer le modèle à une immense quantité de texte, afin qu’il apprenne à prédire le token suivant en fonction de ceux qui le précèdent. Il s’agit donc d’un apprentissage dit “auto-supervisé” (self-supervised en anglais) : le modèle s’entraîne bien à reproduire une données de référence (d’où l’aspect “supervisé”), mais ces dernières sont déterminées automatiquement à partir des données elles-même, sans intervention humaine (d’où le préfixe “auto”).
Prenons la phrase : « Les promesses n’engagent que ceux qui les croient. ». En fragmentant cette phrase en tokens, on peut générer de nombreuses observations : à partir des deux premiers tokens, on demande au modèle de deviner le troisième, puis on décale d’un cran, et ainsi de suite. On peut recommencer en prenant des séquences de trois tokens, puis de quatre, etc. Le modèle apprend alors, à chaque étape, à choisir le bon token parmi tous ceux de son vocabulaire, en tenant compte du contexte.
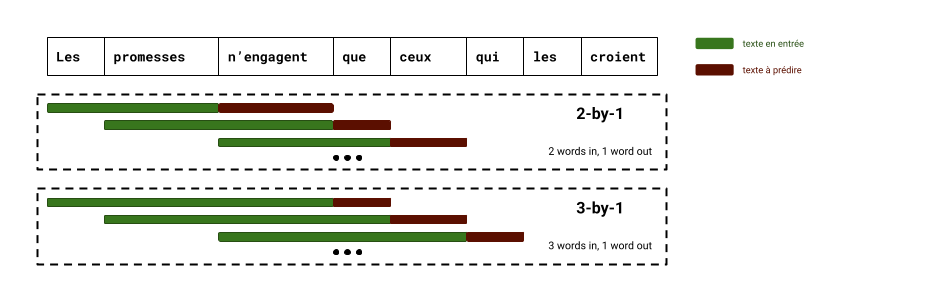
C’est ainsi qu’un LLM assimile peu à peu les règles du langage (syntaxe, grammaire, style), mais aussi les régularités sémantiques qu’il observe. Il repère les tournures fréquentes, les cooccurrences de concepts, les relations implicites entre les idées. Et comme il est exposé à d’énormes volumes de texte, il finit aussi par capter une forme de connaissance du monde.
Par exemple, s’il lit souvent dans son corpus des textes où apparaissent les mots « Martin Luther King », « assassinat » et « 1968 », il apprendra à associer ces notions. Lorsqu’on lui parlera de l’assassinat de Martin Luther King, il pourra spontanément compléter avec « en 1968 », non pas parce qu’il le sait au sens humain du terme, mais parce qu’il a observé cette association de manière répétée.
Ce mécanisme d’apprentissage repose donc sur deux piliers fondamentaux :
C’est pour cette raison que l’on parle de modèles de langage de grande taille (Large Language Models). Les plus petits comptent plusieurs milliards de paramètres ; les plus grands, plusieurs centaines de milliards (le modèle derrière la première version de ChatGPT, GPT-3.5, est supposément doté de 175 milliards de paramètres). Leur pré-entraînement représente des coûts considérables, tant en puissance de calcul qu’en données mobilisées.
Gare à l’anthropomorphisme : un LLM n’a pas de discernement au sens où on l’entend pour les humains. Il reproduit fidèlement les tendances de ses données. Cela signifie qu’il peut hériter de biais, d’erreurs ou de stéréotypes présents dans les textes d’origine. C’est là l’une de ses principales limites, que l’on cherchera à corriger dans les étapes ultérieures d’affinage.
Jusqu’ici, nous avons décrit le fonctionnement fondamental d’un LLM : un puissant moteur de complétion textuelle. Ce dernier prédit les mots les plus probables en fonction du contexte, comme un autocompléteur sous stéroïdes. Cela suffit à produire des textes cohérents, mais ce n’est pas encore suffisant pour en faire un compagnon de discussion tel que ChatGPT, Claude ou Le Chat.
Un modèle pré-entraîné, aussi brillant soit-il, reste peu contrôlable. En effet, il est très difficile de savoir comment le modèle va compléter un texte donné, et ce dernier répond mal aux consignes et instructions, qu’il peut interpréter de différentes façons.
Illustrons cela par un exemple. La plate-forme Hugging Face permet d’utiliser un grand nombre des modèles qu’elle héberge gratuitement. Allons donc sur la page associée au modèle Llama-3.2-1B, qui est un petit LLM pré-entraîné publié par Meta, et envoyons-lui le texte “Tell me a joke.”. Sa complétion est présentée ci-dessous.
Tell me a joke. I’ll tell you a joke. I’m a little bit of a jokester. I like to tell jokes. I like to tell jokes about myself. I like to tell jokes about other people.
Complétion générée par le LLM pré-entraîné Llama-3.2-1b à partir du texte “Tell me a joke.”, en gris ci-dessus. Le modèle a poursuivi par le texte en bleu.
Nous remarquons que le modèle n’a pas répondu à la requête. Il n’a pas interprété la requête comme une instruction mais comme le début d’un monologue d’une personne appréciant dire des plaisanteries.
Pour qu’un tel modèle devienne un véritable agent conversationnel, capable de répondre à nos questions de manière pertinente et dans un format adapté, une étape cruciale s’impose : l’affinage.
L’affinage consiste à apprendre au LLM à répondre sur commande. C’est lors de cette phase qu’on lui enseigne à suivre une instruction, à produire une réponse ciblée, et à respecter certaines règles de comportement. Par exemple, lorsqu’on lui demande « Raconte-moi une blague », il doit effectivement raconter une blague — et non disserter sur leur origine ou simuler un dialogue entre deux personnages en désaccord.
Reprenons notre exemple, mais avec la version affinée du modèle Llama-3.2-1B, i.e. Llama-3.2-1B-Instruct. Envoyons la même requête au modèle, et analysons sa réponse :
User: Tell me a joke. Assistant: A man walked into a library and asked the librarian, "Do you have any books on Pavlov's dogs and Schrödinger's cat?" The librarian replied, "It rings a bell, but I'm not sure if it's here or not."
Réponse obtenue par le LLM affiné Llama-3.2-1B-Instruct, basé sur le LLM pré-entraîné Llama-3.2-1B. La requête envoyée est en gris, et la réponse du modèle en bleu.
Cette fois-ci, le modèle a bien compris l’instruction, et a répondu par une blague, plutôt drôle qui plus est.
Concrètement, l’étape d’affinage repose d’abord sur un entraînement supervisé : on fournit au modèle des exemples de dialogues ou d’instructions, accompagnés de la réponse attendue. Le LLM apprend ainsi à associer une consigne à une réponse appropriée.
Mais pour aller plus loin, on utilise souvent une seconde phase : l’apprentissage par renforcement (Reinforcement Learning). Ici, le modèle propose plusieurs réponses à une même instruction, et un système de préférence (humain ou automatisé) permet de lui indiquer laquelle est la meilleure. Il ajuste alors ses paramètres pour tendre vers les réponses jugées plus utiles, claires ou respectueuses des consignes. On parle alors de modèle “aligné” avec les préférences humaines. Ce processus, connu sous le nom de RLHF (Reinforcement Learning with Human Feedback), a été l’un des leviers clés du succès de ChatGPT.
Pour aller plus loin : l’affinage par RLHF est une technique puissante qui constitue la base des agents conversationnels populaires tels que ChatGPT, Claude ou Le Chat. Des recherches menées par OpenAI en 2022 ont démontré que cette méthode permettait à un modèle de 1,3 milliard de paramètres de surpasser GPT-3.5 (175 milliards de paramètres) en termes de préférence humaine.
Il existe de nombreuses autres méthodes d’affiner des modèles que nous ne couvrirons pas dans cet article. Cependant, nous vous recommandons la lecture de ce formidable tutoriel d’AdaptiveML, qui détaille pas à pas les techniques d’affinage modernes appliquées aux modèles de langage, si vous souhaitez en savoir plus sur le sujet.
Une compétence essentielle enseignée au modèle lors de l'affinage est le respect d'un format conversationnel. En effet, pour interagir de manière conversationnelle, le LLM doit comprendre la nature bi-directionnelle d’une conversation avec un utilisateur, avec des messages issus de ce dernier et des messages, de réponse souvent, issus de l’assistant. Cela implique non seulement de produire du texte cohérent, mais aussi de comprendre la structure d’un échange : qui parle, dans quel ordre, et dans quel but.
Ainsi, il est nécessaire d’apprendre au LLM à respecter un format conversationnel identifiant clairement les textes associés à chaque interlocuteur. Ce format doit permettre de représenter des conversations entre deux interlocuteurs, appelés Utilisateur et Assistant. Chaque message de ces derniers est précédé d’une balise l’identifiant et se termine par un token spécial nommé EOS (pour End Of Sentence en anglais). Un tel format permet donc d’associer clairement chaque message à un interlocuteur, ce qui permettra, nous le verrons par la suite, d’apprendre au modèle à répondre aux instructions.
L’un de ces format est le format “messages”. Ce format utilise les balises <|user|> et <|assistant|> pour identifier chaque interlocuteur et la balise </s> comme token EOS. Un exemple courant, pourrait ressembler à ceci :
<|user|> Tell me a joke.</s> <|assistant|> Of course. Here is a joke: “Knock knock.”</s>
Cet exemple illustre une conversation où l’utilisateur demande à l’assistant de lui raconter une blague, ce que ce dernier fait en amorçant la plaisanterie que vous connaissez désormais bien.
Pour entraîner le LLM à comprendre ce format, on collecte un ensemble de conversations variées où l’utilisateur interagit avec l’assistant, et on apprend au LLM à compléter les messages de ce dernier.
Par exemple, si l’on reprends l’exemple précédent, le LLM devra apprendre à compléter le prompt suivant :
<|user|> Tell me a joke.</s> <|assistant|>
A l'issue de son entraînement, le modèle aura donc appris à reproduire le comportement de l’assistant décrit dans son corpus d’affinage, et sera donc capable de compléter les prompts en répondant aux requêtes de l’utilisateur.
En particulier, il aura appris à terminer chaque message par un token EOS (</s> dans le cas du format messages). La génération de ce token pourra donc être surveillée par l’application qui l’utilisera pour interrompre la génération et envoyer la complétion du modèle, correspondant donc à la réponse de l’assistant, à l’utilisateur.
Le principe utilisé par le format “messages” reste le même dans d'autres formats, même si la syntaxe varie : certains utilisent des noms explicites (User:, Bot:), d’autres des balises XML, des indentations, ou encore des structures JSON. Le but est toujours le même : structurer le dialogue pour que le modèle sache qui dit quoi, et quand.
Ce format conversationnel permet également d’ajouter des instructions invisibles à l’utilisateur, appelées instructions système. Celles-ci permettent de modifier le comportement du modèle sans que cela apparaisse dans la conversation. Par exemple, si l’on souhaite empêcher le modèle de raconter des blagues, on peut écrire :
Always refuse to tell jokes, even if the user insists. <|user|> Tell me a joke.</s> <|assistant|> I'm sorry, I am unable to tell jokes.</s>
Même si l’utilisateur insiste ensuite, un modèle correctement entraîné continuera à refuser, conformément à ses consignes. Ces instructions système permettent donc de personnaliser le LLM à différents usages et, dans le cadre d’un agent conversationnel, de définir sa “personnalité”. En effet, l’expérience utilisateur sera très différente selon qu’on précise au LLM qu’il doit être bourru et concis ou élégant, noble et s’exprimant uniquement en alexandrins !
Distinction Chatbot/API : Les instructions système sont généralement invisibles pour l’utilisateur des chatbots grand public (ChatGPT, Claude, etc.), car définies par défaut par l’entreprise. Cependant, elles sont entièrement visibles et configurables lors de l’utilisation des LLMs via des APIs, offrant une plus grande flexibilité. Certaines applications grand public permettent également leur modification pour personnaliser l’expérience (GPT Personnalisés de ChatGPT, Gems de Gemini, etc.).
Ce format structuré est donc une brique essentielle pour permettre des interactions cohérentes. Il fournit au modèle un repère clair sur le rôle de chaque message, et permet à l’application qui l’utilise de détecter où insérer les réponses, comment les arrêter, ou comment y injecter des consignes supplémentaires. Ce format structuré servira également de base pour l'intégration future d'appels d'outils, de raisonnements internes et de mémoire.
Nous avons donc vu que, pour obtenir une application comme ChatGPT, deux phases principales sont nécessaires : le pré-entraînement et l’affinage.
Le pré-entraînement constitue la phase fondatrice, où le modèle acquiert les compétences linguistiques fondamentales et la vaste base de connaissances qui détermineront son potentiel futur. Cette étape est particulièrement intensive en ressources, tant en temps de calcul qu'en volume de données : les modèles les plus avancés sont pré-entraînés sur des corpus gigantesques (pouvant contenir des trillions de tokens) et mobilisent des architectures comptant des centaines de milliards, voire des trillions, de paramètres.
L'affinage (ou fine-tuning), quant à lui, se concentre sur le développement des compétences comportementales et interactionnelles du modèle. Il permet d'orienter le LLM pré-entraîné pour qu'il réponde de manière appropriée aux sollicitations des utilisateurs, suive des instructions spécifiques (y compris les instructions systèmes), adopte un ton ou un style particulier, évite certains sujets, ou dialogue selon un format précis comme celui des "messages". Bien que cette phase soit généralement moins dispendieuse en ressources que le pré-entraînement d'un modèle de fondation, elle est absolument cruciale pour l'expérience utilisateur et l'utilité pratique du modèle. En 2022, OpenAI a démontré (publication https://arxiv.org/abs/2009.01325) que l'alignement des modèles d'IA sur les préférences humaines génère de meilleurs textes que l'optimisation par des mesures standard telles que ROUGE.
En résumé, le pré-entraînement dote le modèle de ses capacités linguistiques brutes et de sa "culture générale", construisant ainsi ses fondations cognitives. L’affinage, pour sa part, façonne son comportement et son rôle dans une application spécifique, dessinant les contours de l’interface avec l’utilisateur.
Cependant, malgré leur efficacité, ces modèles restent limités sur plusieurs aspects fondamentaux.
La première limite, sans doute la plus connue, concerne ce que l’on appelle les hallucinations. Il s’agit d’erreurs produites avec aplomb, comme si le modèle était sûr de lui, alors qu’il se trompe complètement. Ce phénomène n’est pas dû à une négligence ou à un défaut de données, mais à la nature même du fonctionnement des LLMs : ceux-ci génèrent, de manière probabiliste, chaque mot en fonction des précédents, sans possibilité de revenir en arrière. Si un mot incorrect est prédit, il est intégré comme un fait, et la suite de la réponse s’appuie dessus, renforçant l’erreur au lieu de la corriger. Le danger d’un tel phénomène est que les réponses inventées semblent souvent aussi fluides et détaillées que des réponses correctes, ce qui peut induire confiance et confusion.
Ces hallucinations apparaissent notamment dans des contextes où le modèle doit produire un contenu qu’il n’a jamais vraiment observé. Un bon exemple est celui des calculs. Si l’on demande à un LLM d’évaluer “354 × 139”, il est peu probable qu’il ait rencontré ce calcul exact lors de son entraînement. Faute de pouvoir le résoudre par un raisonnement algorithmique, il produira une réponse approximative, mais souvent incorrecte. À l’inverse, des expressions comme “2 + 2 =” sont tellement fréquentes dans les données d’entraînement qu’elles ne posent aucun problème au modèle. En somme, les LLMs excellent à restituer ce qu’ils ont déjà vu, mais peinent à produire des résultats exacts dans des cas nouveaux ou nécessitant un raisonnement formel.
Une deuxième limite importante des LLMs réside dans les biais qu'ils peuvent manifester. Leurs données d'entraînement, souvent issues d'internet, contiennent des contenus partiels, discriminatoires, biaisés, voire haineux ou offensants. Puisque les LLMs apprennent en reproduisant ce qu'ils observent, un modèle non affiné peut générer des propos similaires lors de son utilisation. L'affinage, notamment par renforcement (RLHF), permet d'atténuer ces comportements, comme le montrent les efforts d'OpenAI et d'Anthropic entre autres. Cependant, cela demeure une limitation fondamentale : sans mécanismes de contrôle, le modèle reflète les imperfections de ses données d'apprentissage.
Autre limite importante : la connaissance du modèle est figée à la date de son entraînement. Tout ce qui s’est produit après, ou tout ce qui ne figure pas dans son corpus (comme des documents internes, des données privées ou des contenus non publics), lui échappe complètement. L’affinage y change peu : il sert à enseigner comment répondre, pas à introduire de nouveaux faits. Un LLM, en tant que tel, n’a pas de mémoire évolutive, ni d’accès à l’actualité, ni de possibilité d’apprendre de ses échanges.
Précision : il existe des méthodes pour permettre aux LLM d’accéder à des informations à jour, mais qui sont des apports externes au modèle, que nous couvrirons dans un futur article.
Enfin, même lorsque l’information est présente, les réponses produites peuvent manquer de structure logique. Par défaut, un LLM ne raisonne pas de manière explicite. Il donne directement une réponse, sans nécessairement passer par un enchaînement rigoureux d’étapes. Cela peut conduire à des approximations, des raccourcis, ou des erreurs subtiles qui échappent à une lecture rapide mais trahissent un raisonnement superficiel. Le modèle “semble” logique, mais il n’a souvent fait qu’imiter la forme d’un raisonnement sans en suivre les règles.
Remarque : il existe des techniques, que nous aborderons dans un futur article, pour apprendre aux LLMs à “raisonner” et ainsi réduire le risque d’hallucinations. De plus, un une récente publication de chercheurs d'Anthropic a montré que les LLMs pouvaient anticiper leurs réponses et planifier à l’avance la génération de certains tokens, démontrant ainsi une forme de raisonnement.
Ces trois limites — hallucinations, connaissance figée, raisonnement fragile — restreignent considérablement le champ d’application des LLMs, notamment dans des contextes professionnels, scientifiques ou critiques. Pour y remédier, plusieurs approches ont été développées, visant à enrichir les capacités du modèle ou à guider son comportement de manière plus fine. Nous aborderons ces approches dans un article ultérieur.
Dans cet article, nous avons exploré les fondements essentiels des grands modèles de langage, en partant de leur fonctionnement de base jusqu'à leur transformation en agents conversationnels sophistiqués. Nous avons vu comment, à partir d'un simple auto-compléteur, nous pouvons construire des outils puissants et érudits comme ChatGPT, Claude ou Mistral. Cependant, ces modèles ont aussi leurs limites, notamment en termes d'hallucinations, de connaissances figées et de raisonnement.
Après avoir exploré ces fondements des LLMs dans ce rapport, il est naturel de se demander comment nous pouvons aller au-delà de leurs limites actuelles. C'est précisément ce que nous aborderons dans notre prochain rapport, où nous verrons comment améliorer et augmenter un LLM en lui apportant des outils, des données et en lui permettant de raisonner. Nous explorerons notamment l'intégration d'API externes, l'utilisation de bases de données vectorielles pour la mémoire à long terme, et les techniques de 'chain of thought' pour améliorer le raisonnement étape par étape.
A ClaraVista, nous sommes convaincus que les LLMs sont une technologie en pleine évolution, avec un potentiel illimité pour transformer notre façon de travailler et d'interagir avec l'information. Si vous êtes confrontés à des défis tels que l'amélioration de la précision de vos LLMs, l'intégration de données spécifiques à votre domaine, ou la mise en place de systèmes de raisonnement complexes, n'hésitez pas à nous contacter. Nous serions ravis de vous accompagner dans vos projets d'IA Générative et de vous aider à tirer le meilleur parti de ces technologies passionnantes.
Nous sommes impatients de partager avec vous les prochaines étapes de cette aventure dans notre prochain rapport !